Case Study
1 Introduction
The last decade has seen a paradigm shift in computing infrastructure. Systems are becoming more and more ephemeral, abstracted, and distributed. Innovations in computing infrastructure and software architectures have yielded simpler components at higher levels of abstraction, allowing engineers to deploy and stitch together many more different kinds of software components today, resulting in vastly increased complexity.
This complexity has only been increasing as more and more companies adopt a multi-cloud strategy and utilize services across cloud providers.
1.1 What is Pilot?
Pilot is an open-source, multi-cloud framework that provisions an internal PaaS with a workflow-agnostic build, deploy, and release pipeline. Our team built Pilot in order to help small teams tackle the challenges of adopting a multi-cloud strategy.
Pilot enables you to deploy, manage, and quickly iterate upon your applications regardless of the complexity of the underlying architecture. With Pilot, you don't have to learn the specifics of a certain service offered by a cloud provider - such as Amazon Web Service's Elastic Container Service. You can simply give Pilot some cursory information about your application, and Pilot will handle the rest. The same goes for other cloud providers, such as Google Cloud Platform.
All of this allows developers to quickly get an application up and running on their desired cloud provider without having to trawl through pages and pages of documentation or learn the ins-and-outs of how that cloud provider works.
2 Multi-Cloud Strategy
2.1 ACME: An Example User Story
To discuss the adoption of a multi-cloud strategy, let's use an example company ACME. ACME's application is currently a monolithic application - all business logic is handled within the same code-base. And in ACME's case, on a bare-metal server that they own. This has been ACME's tried and true approach for awhile now; however, this infrastructure has limits. With a single server, they're limited by physical bottlenecks like the server's memory and networking capabilities.
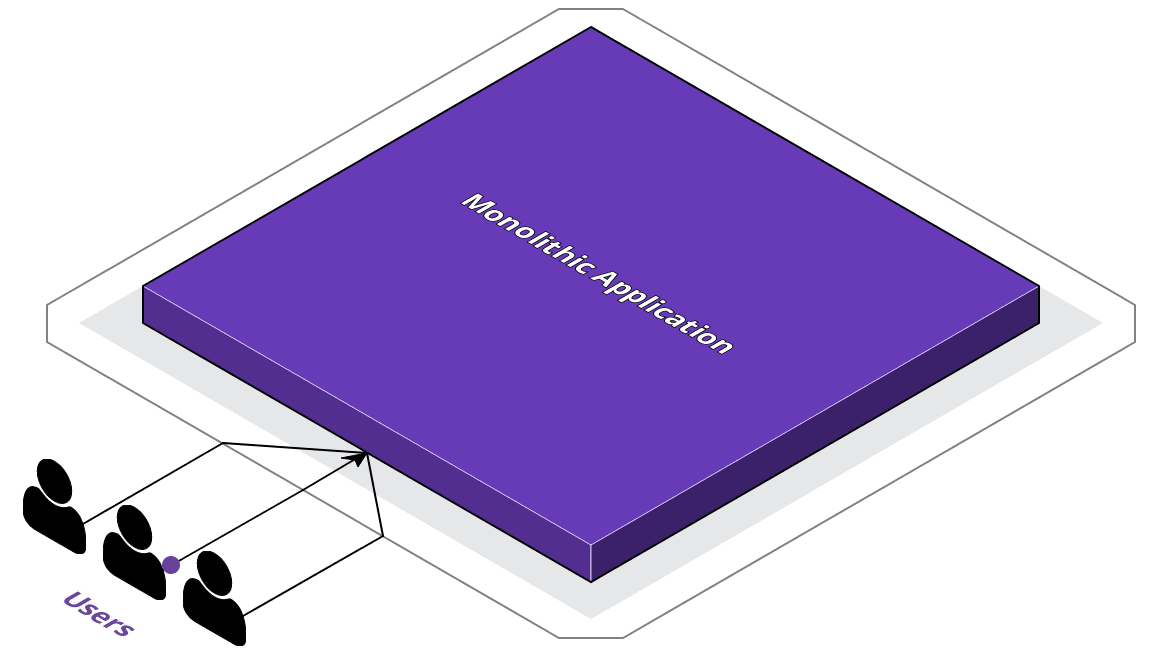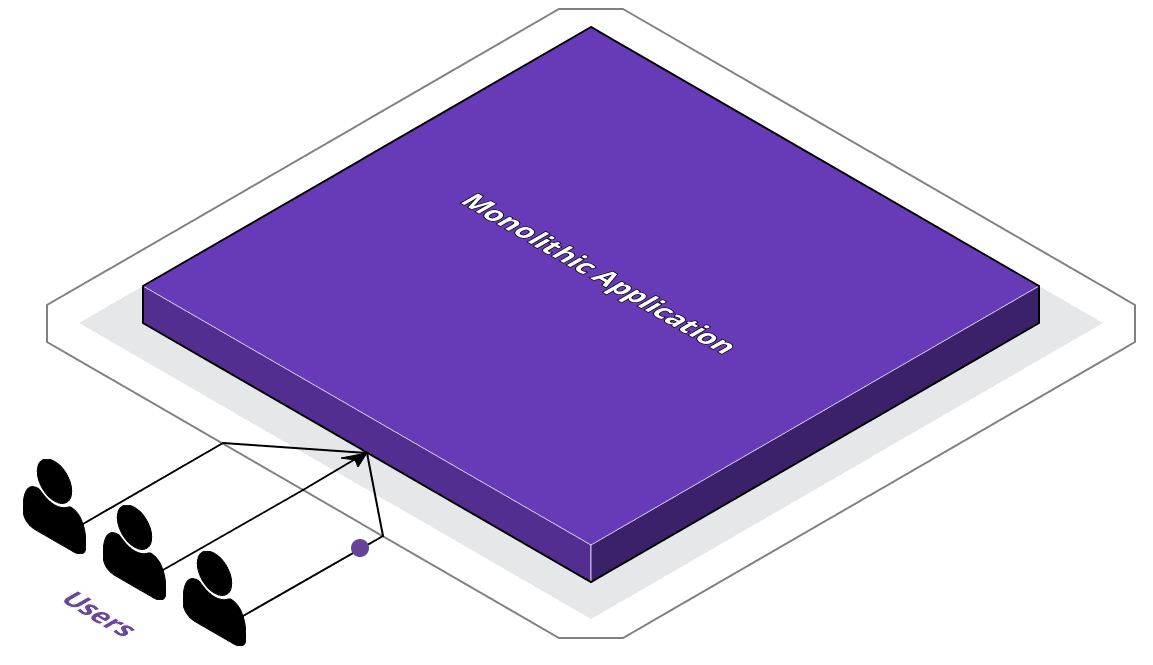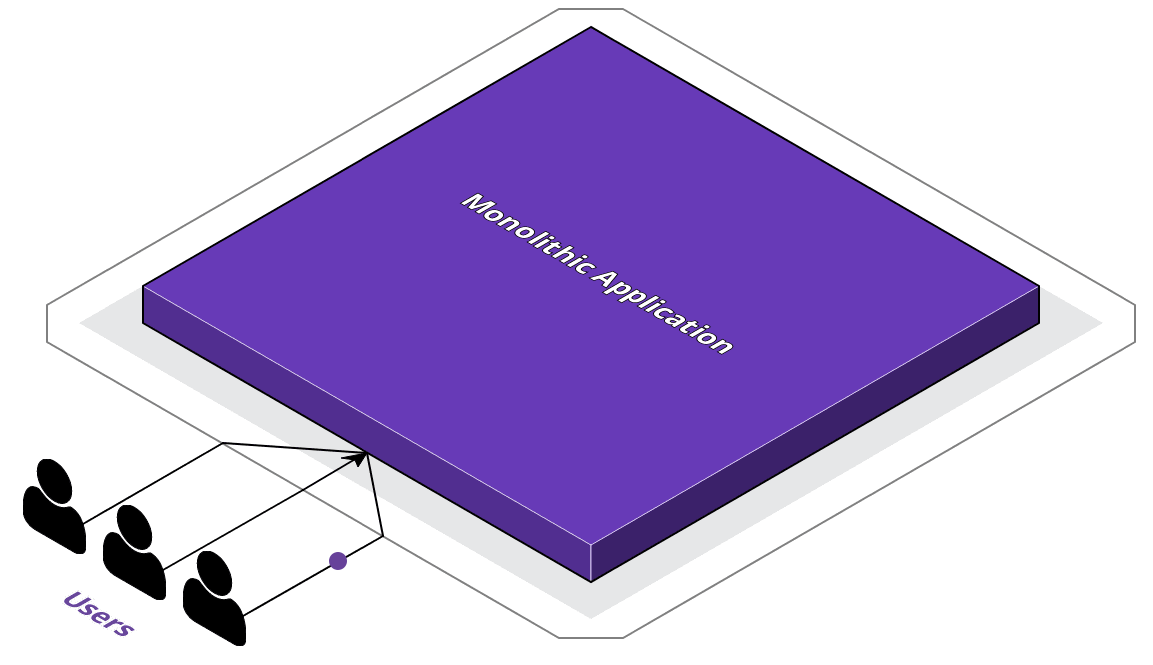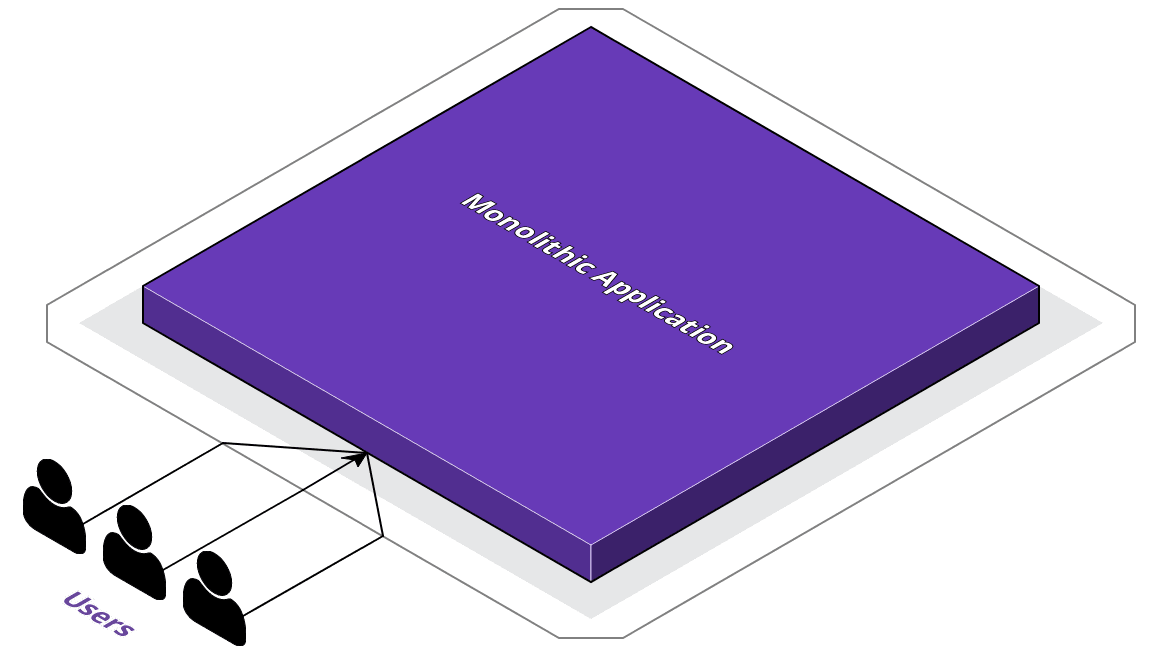
Because of this, ACME's CTO has been working on their digital transformation plans. As part of their digital transformation, the CTO has informed the development team of the two most important goals:
- breaking apart their monolith into microservices
- adopting a multi-cloud, or hybrid cloud, strategy
2.2 Breaking Apart a Monolith
If we look at their monolithic application in more detail, we can see that they've got some distinct, logical services already - in a monolith, these could be classes in an object-oriented language, but otherwise they are just portions of the code-base with a distinct responsibility.
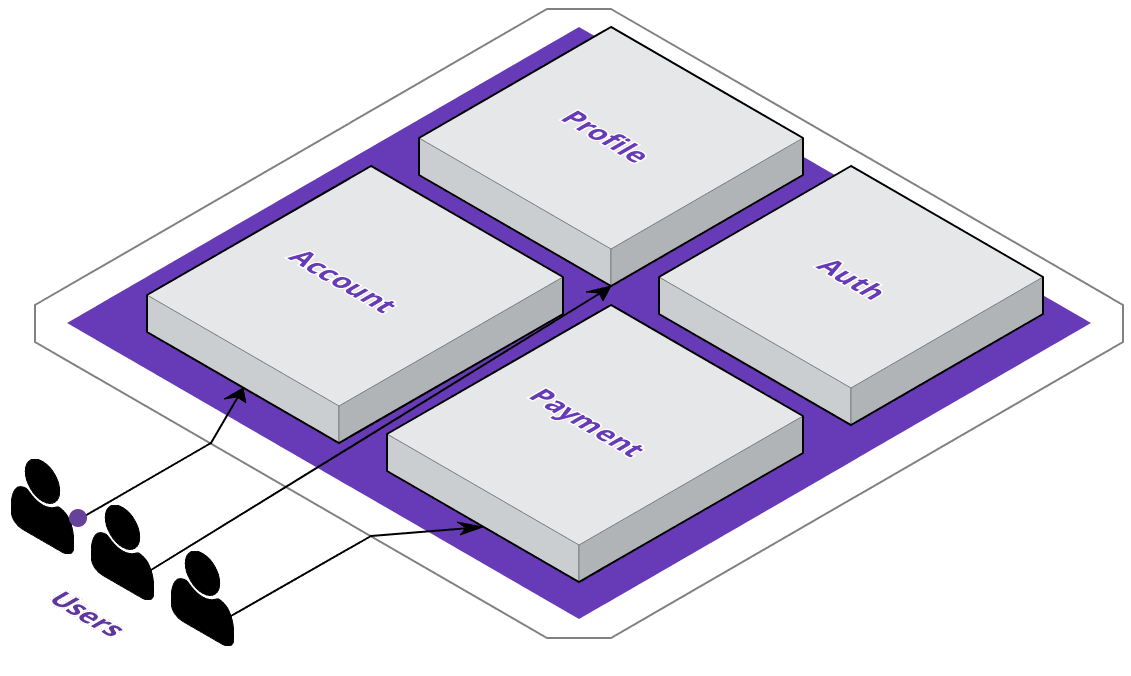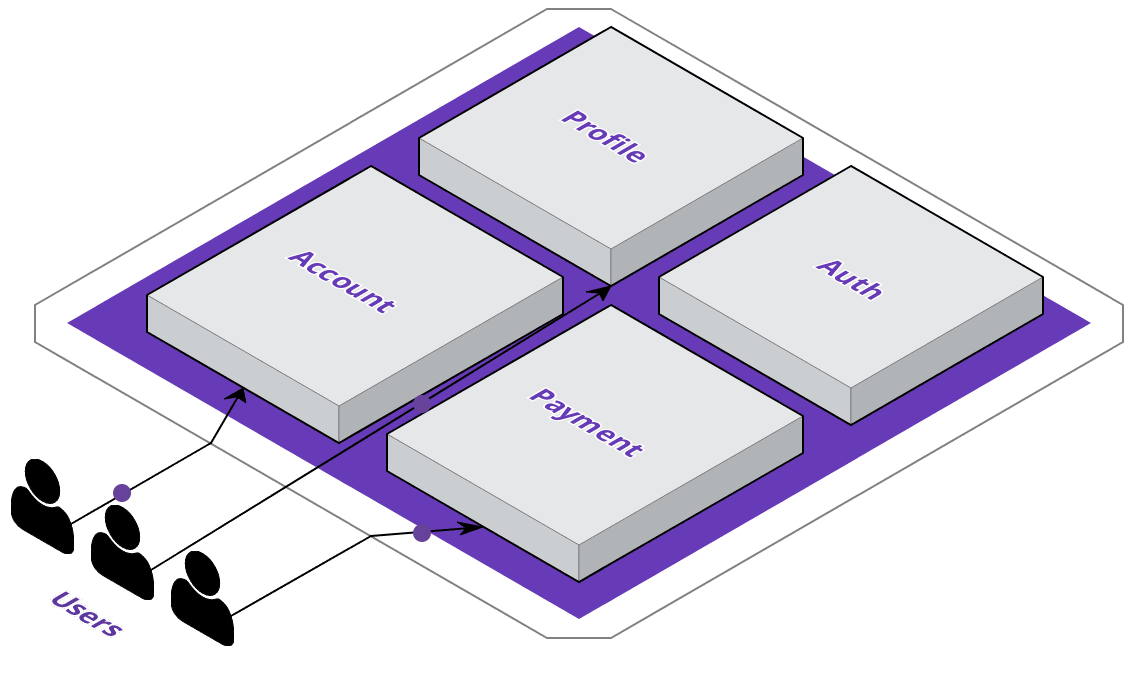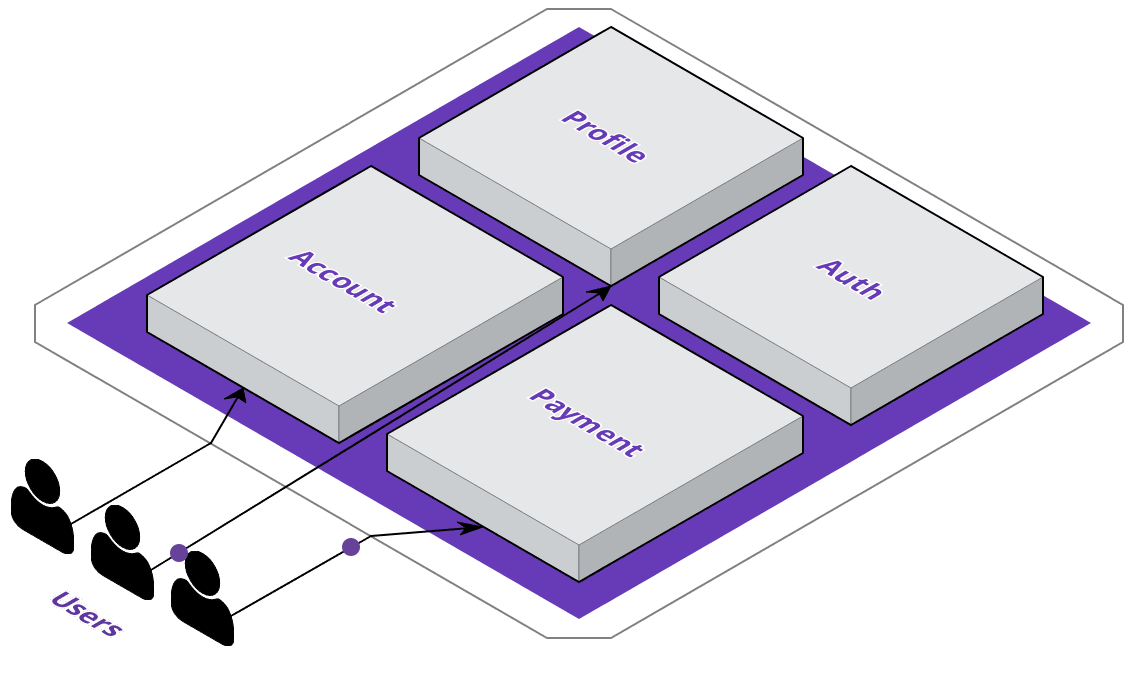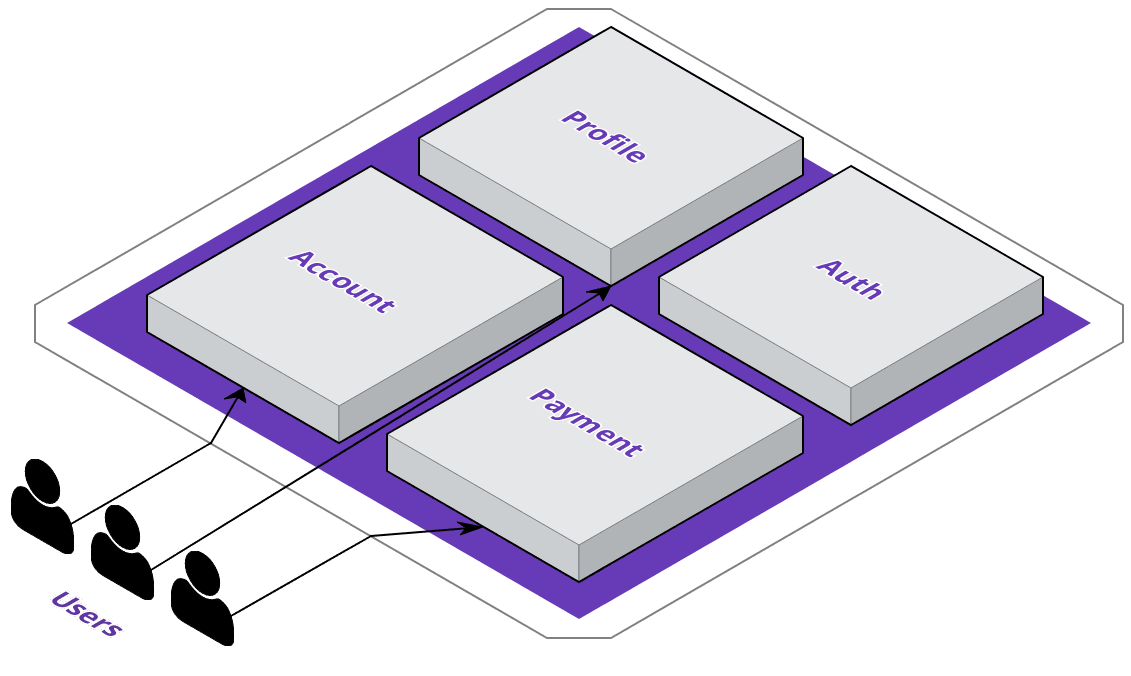
Adopting a microservice approach would mean that rather than portions of the same code-base, services are discrete and are only concerned with their own processes while still being able to communicate with other services. One of the primary benefits of this approach is that it allows services to scale and consume resources independently of one another.
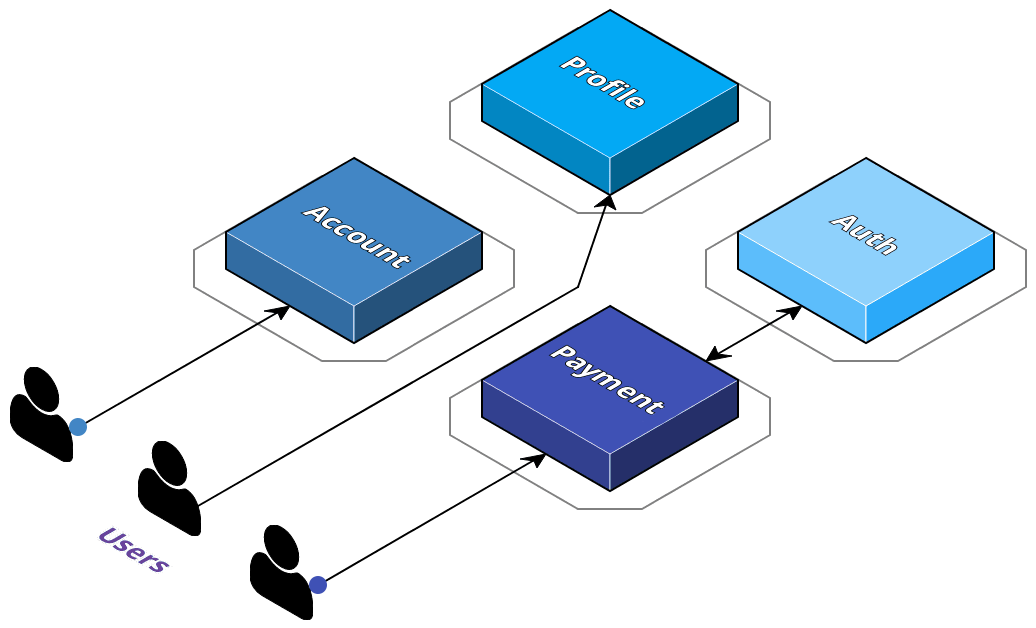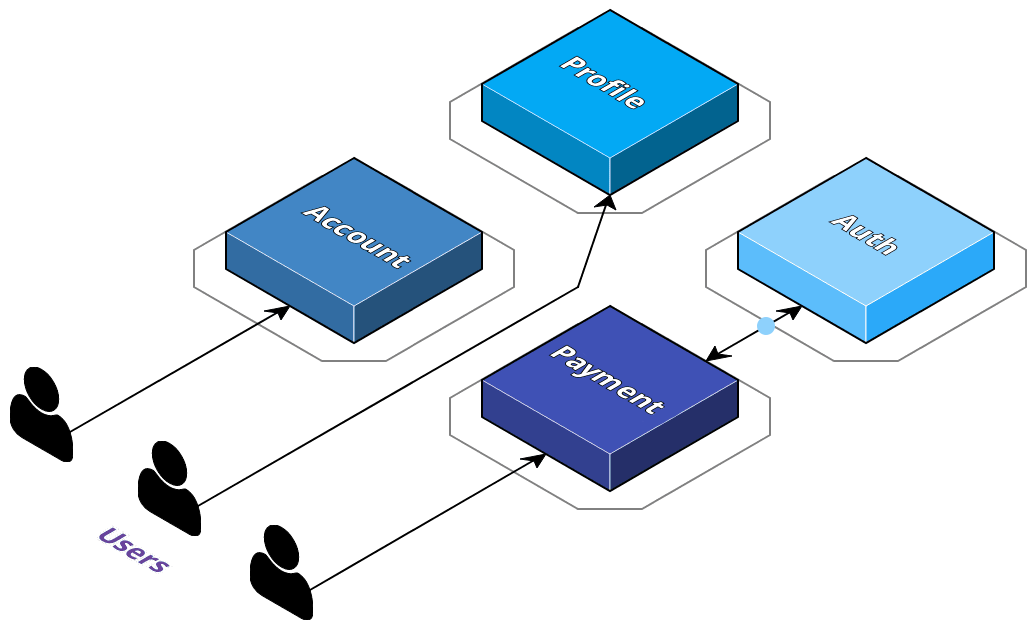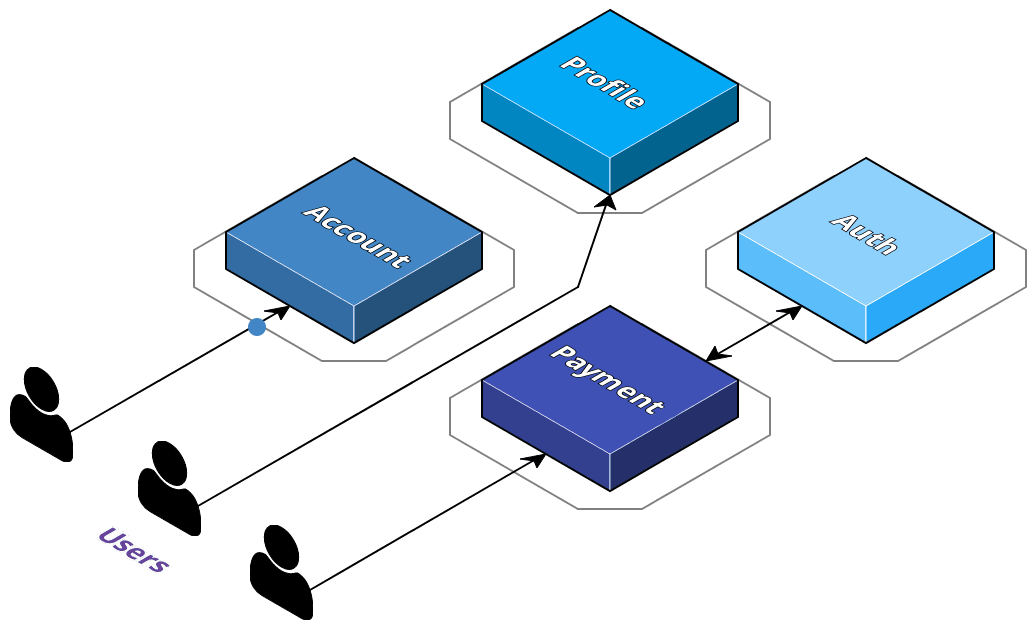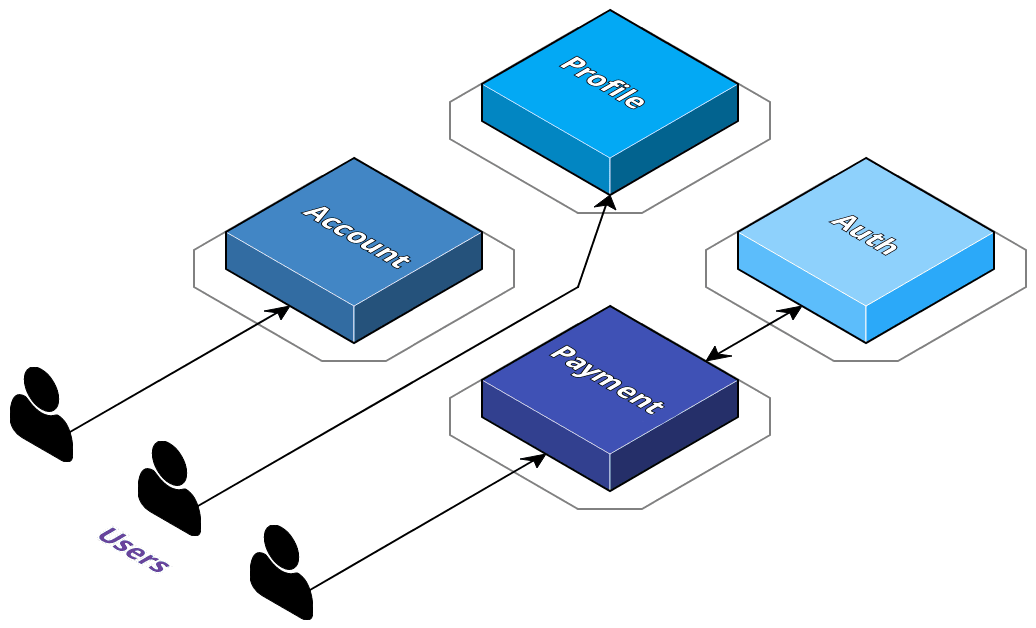
2.3 Adopting a Multi-Cloud Strategy
A multi-cloud strategy means utilizing services provided by multiple cloud providers. There are many reasons a company might adopt this approach, but some common ones are:
- avoiding single-vendor lock-in
- operational resiliency
- security and governance
- emerging technologies
Because of this, many companies have already adopted a multi-cloud strategy. However, adopting this strategy can be difficult, especially for smaller companies. Common inhibitors for teams are:
- lack of in-house skills
- hybrid cloud complexity
- complexity of networking
- lack of tooling
Many small companies also utilize a Platform-as-a-Service, which typically don't provide the flexibility needed for multi-cloud deployments.
3 Platform-as-a-Service
3.1 ACME: Service Extraction
Now that we're familiar with ACME's digital transformation plans, let's see how their development team would go about implementing these changes. The first thing they're going to do is identify which service to extract out of the monolith. They want their users to be able to log in to 3rd party websites with their ACME accounts; however, this means that a lot of requests coming in just for authentication could degrade their overall application's performance.
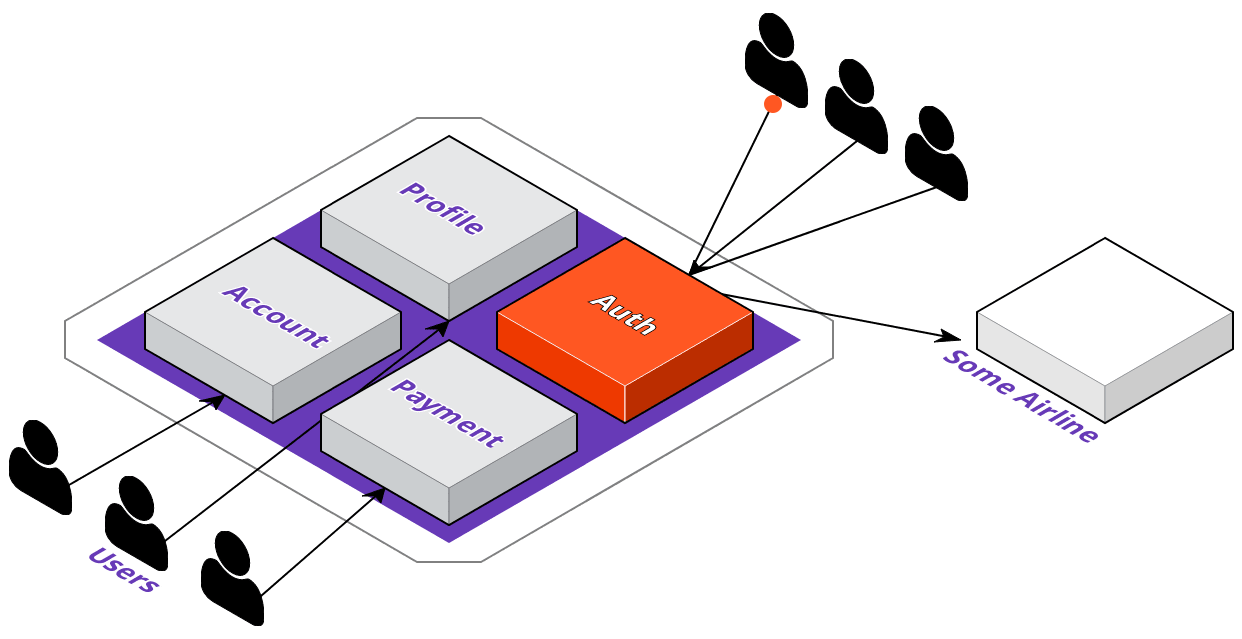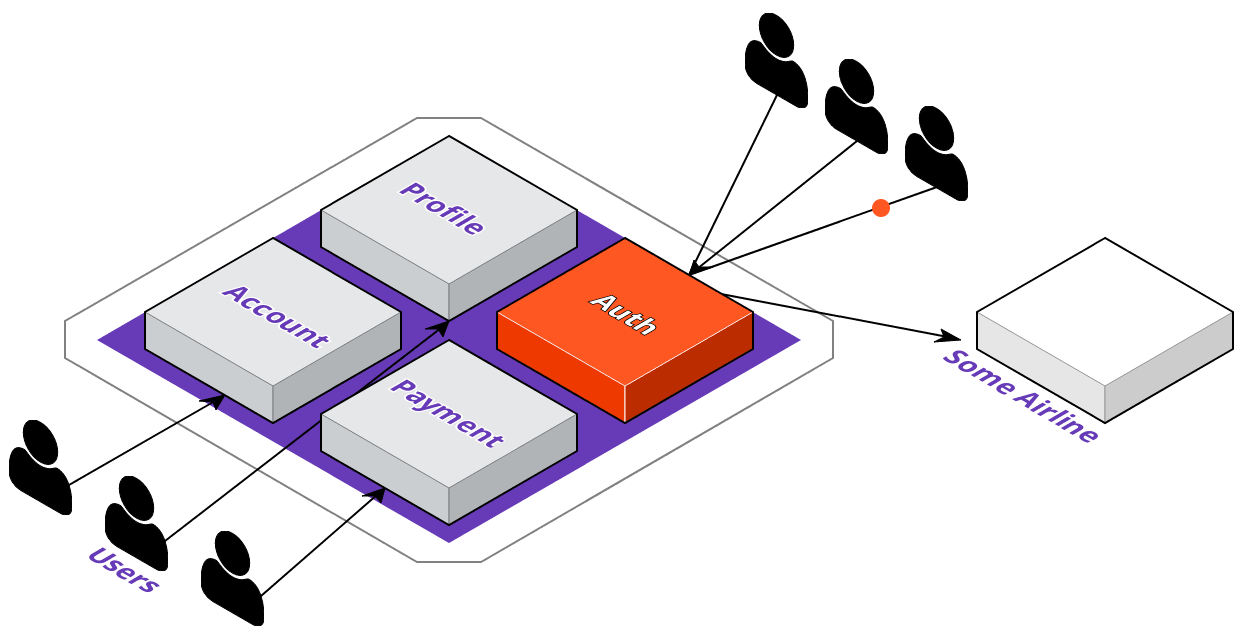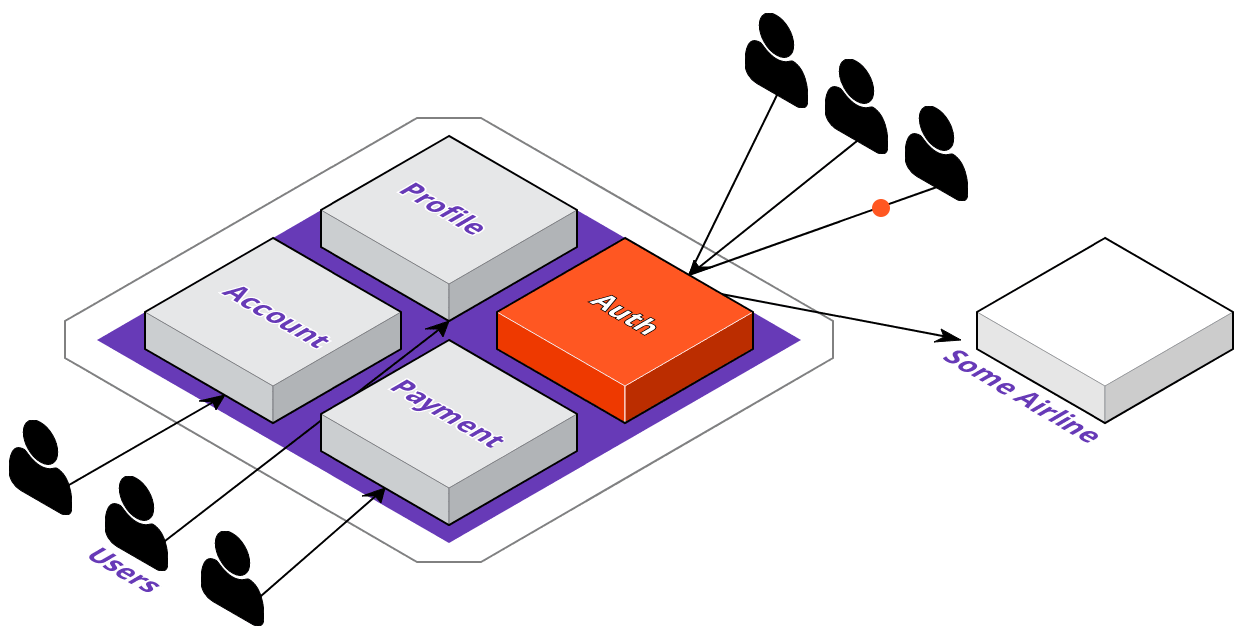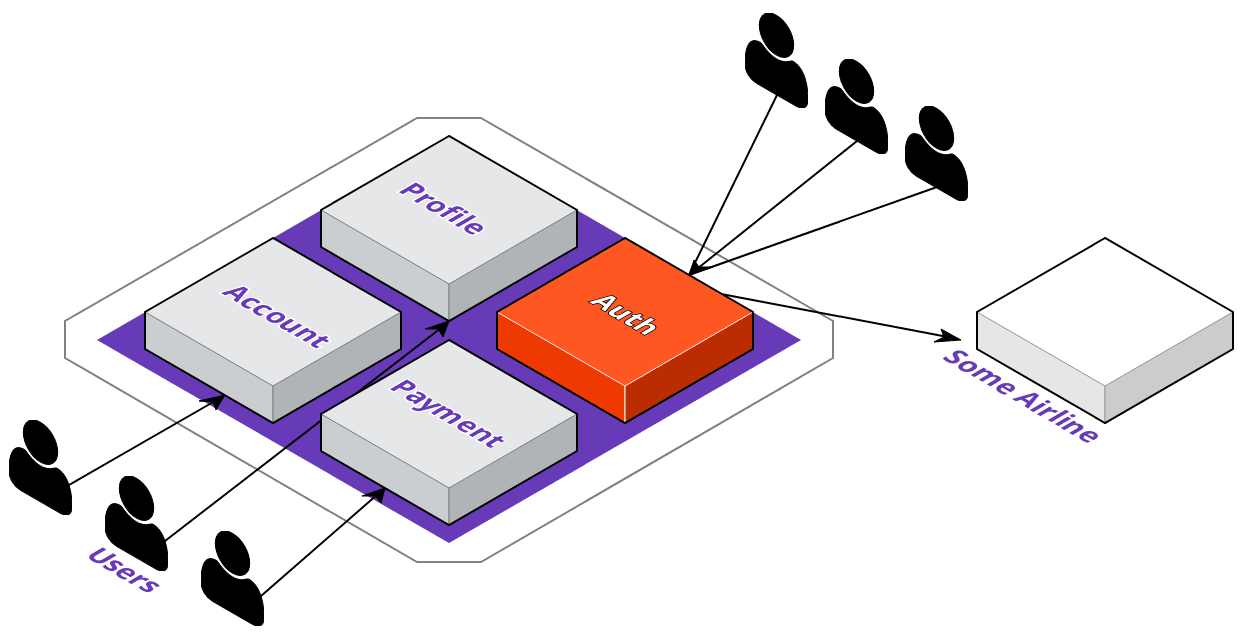
To solve this, they'll extract the auth service out of the monolith, and they'll want to deploy it where the service will be highly available. With that in mind, let's take a look at what the deployment pipeline could look like with a multi-cloud approach.
3.2 Deployment Pipeline
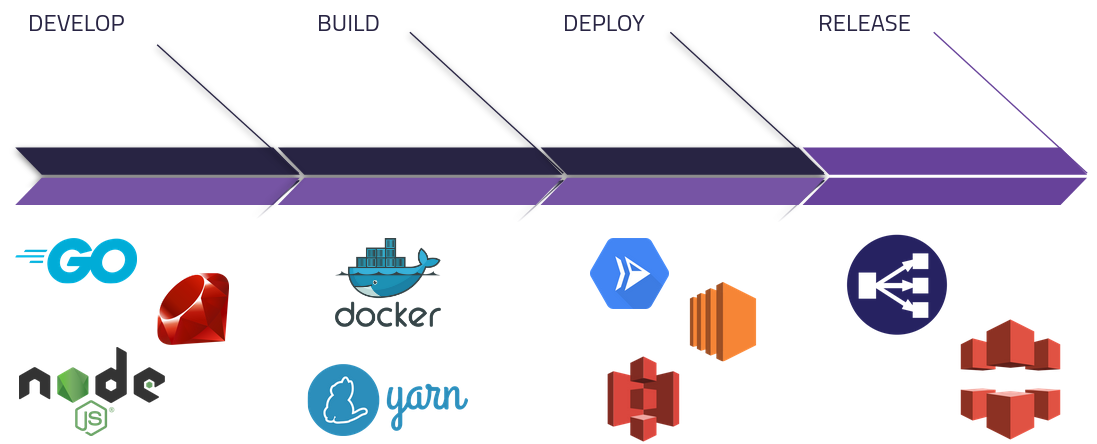
First, a software development team plans, architects, and develops an application.
Then, the source code goes through some sort of build process to produce a runnable artifact. That could be containerizing the application to provide a slim, low-footprint environment for the application to execute in using Docker. Or, it could be compiling code from a frontend framework like React into static files using a package manager like Yarn.
The artifact from the build phase is then used as the application is deployed to the proper hosting solution. There are many solutions out there, such as: Google Cloud Run for container orchestration, AWS EC2 for virtual machines, and AWS S3 for static file hosting.
Finally, any necessary resources for public consumption are configured to interface with an existing deployment - such as setting up an application load balancer to direct network traffic, or configuring a content distribution network like AWS Cloudfront to distribute static files stored in S3.
All this complexity can be difficult to both learn and manage, especially for small development teams with little DevOps experience. This is why Platforms as a Service have arisen.
3.3 PaaS v. Other Solutions
A platform-as-a-service, or PaaS, abstracts away the complexity of the build, deploy, and release cycle. This allows developers to simply focus on their code. Examples of a PaaS are Heroku, and cloud provider-specific platforms like Google's App Engine and Amazon's Elastic Beanstalk.
When using a PaaS, developers generally trade control and configuration away for ease-of-use. Let's look at PaaS compared to other options, like on-premise servers and Infrastructure-as-a-Service.
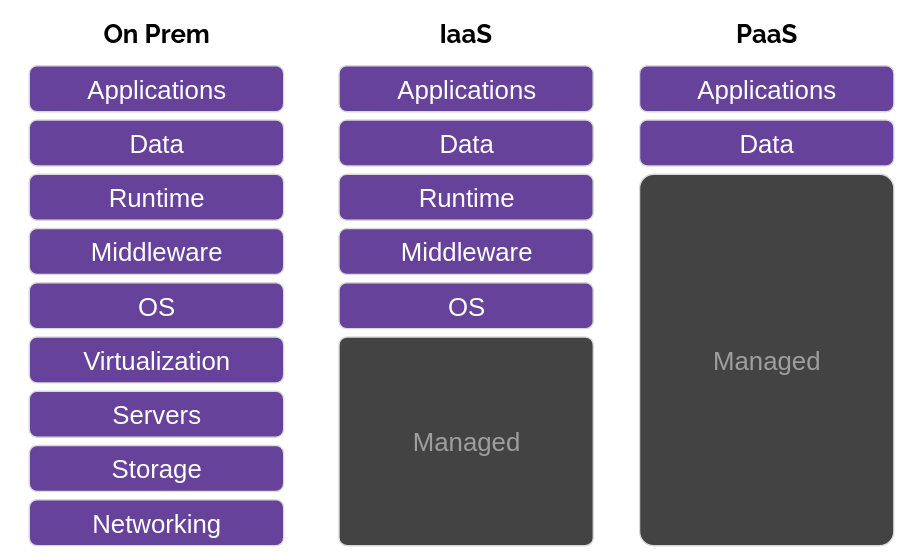
With on-premise servers, you have the most control and configurability of your environment - from your application all the way down to the bare-metal server - however, with that comes a lot of responsibility. With physical servers come physical maintenance - ensuring your server room is properly ventilated and secured are very important to ensuring your services remain stable.
Next, there is Infrastructure-as-a-Service, or IaaS. As the name implies, the service you're paying for is the management and control of those physical servers. You no longer need the overhead of a server room and maintenance, simply spin up a virtual machine and go from there. However, for simply deploying an application, there's still a lot of management and configuration overhead.
This is why PaaS exists - developers can concern themselves with their applications and data, while the platform handles the infrastructure under the hood.
3.4 Internal PaaS
Let's revisit the auth service ACME wants to deploy. They're allowing their users to log in to 3rd party websites with their ACME accounts; however, they know it needs to be highly available since they can't predict the usage patterns of that 3rd party website.
ACME has decided they want to use a PaaS for ease-of-use. They've decided on Google's App Engine, which will handle the build, deploy, and release cycle for their auth service. Under the hood, Google uses their own Cloud Run container orchestrator - which is known to be highly available and scalable.
But now, ACME has another issue. As part of their payment logic, they process payment data, generate invoices, and store them on a local file server. However, their local file server is running out of disk space, and they don't want to keep buying hard drives.
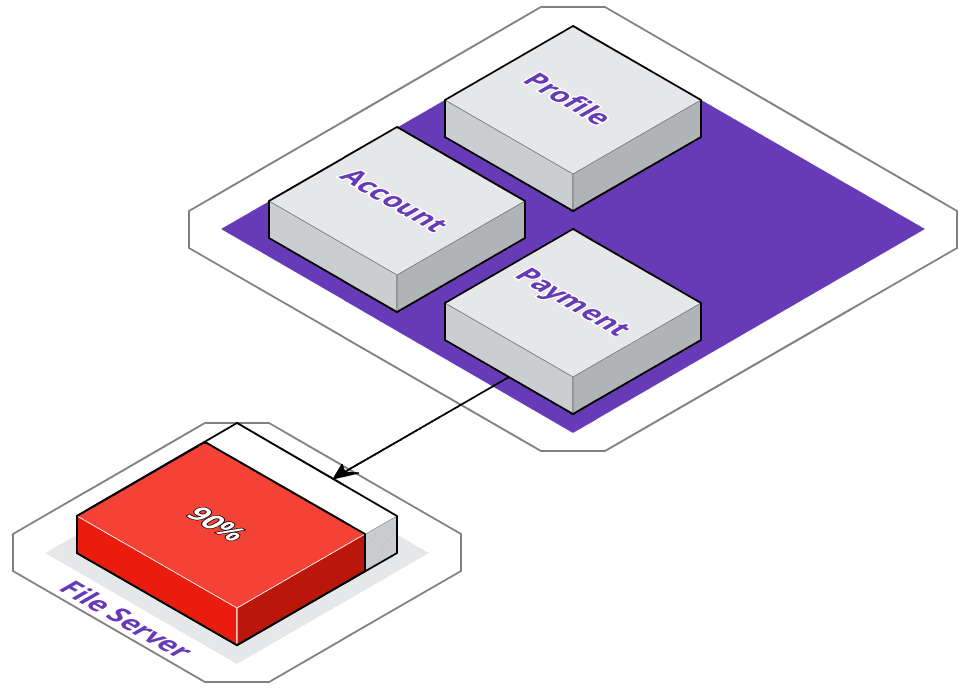
While they could utilize Google's Cloud Storage, they don't want to get locked in to a single vendor so early on in their service extraction process - so, they've decided to migrate their files to Amazon's S3. However, this also means they need to modify their payment service.
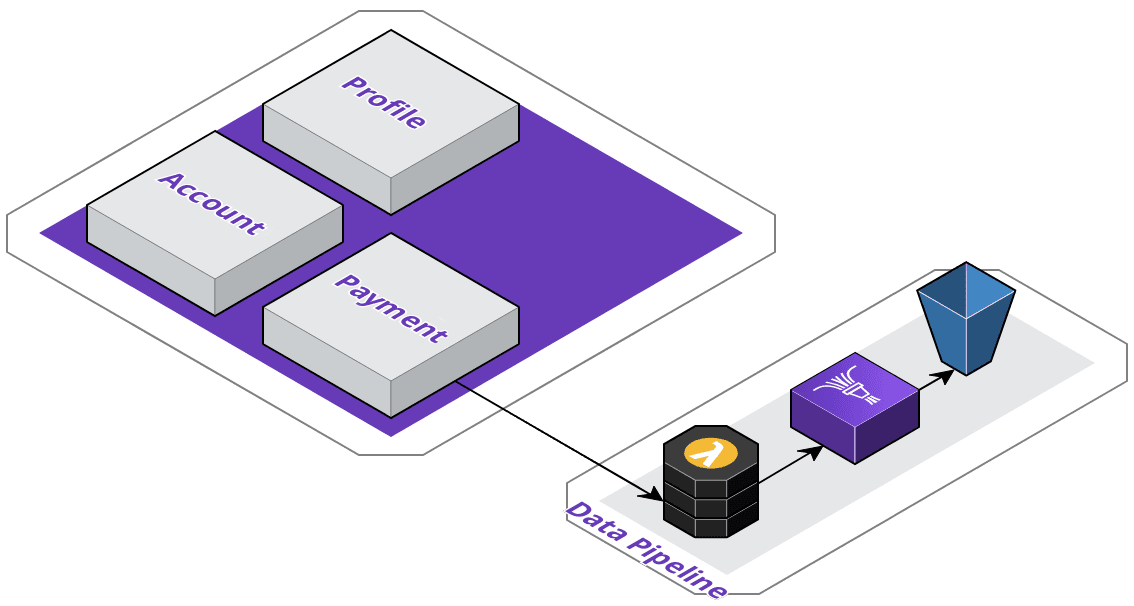
They've decided to design a data pipeline - the application will send invoice data to an AWS Lambda, which will perform any pre-processing before sending it to Firehose, which then streams it into their S3 buckets. As you can see below, with just two services extracted, the application topology is beginning to become more and more complex. They've got one service running on Google Cloud Run via App Engine, and their data pipeline on AWS.
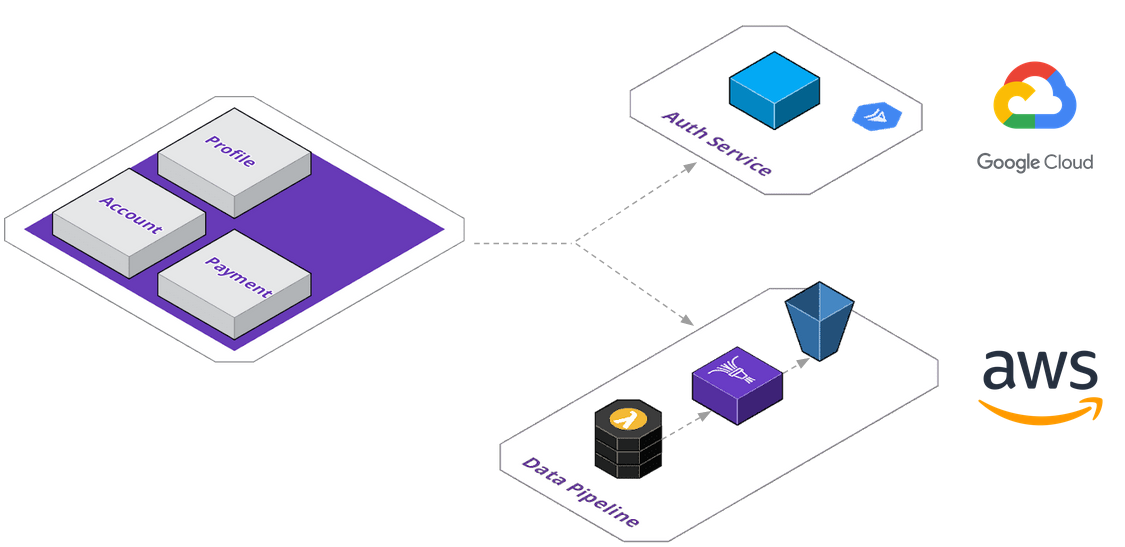
The development team at ACME is getting frustrated with the separated deployment pipelines, and wish they could manage all of this in a unified platform - they've seen companies build their own platform before and are toying with the idea themselves.
Companies like Netflix and Atlassian have built their own platforms. The reasoning behind that is as you initially set up IaaS offerings, you think that managing them will be as simple as setting up some load balancers and pointing them to an autoscaling group of virtual machines, which have access to your resources.
However the reality is that, especially as your application grows, this topology becomes increasingly complex to manage. It's difficult to track down exactly which application is running on which resource, which deployments may be stale and ready to tear down, and overall takes a dedicated team to truly manage in an efficient manner. Both Netflix and Atlassian are large enterprises that can afford to dedicate teams to their platforms - ACME isn't.
And that is why we built Pilot - a tool that can assist small development teams without the resources and expertise that larger companies might have at their disposal to tackle complex multi-cloud deployments. Because Pilot acts as an internal PaaS, this also means ACME would still own all of the infrastructure and services Pilot utilizes.
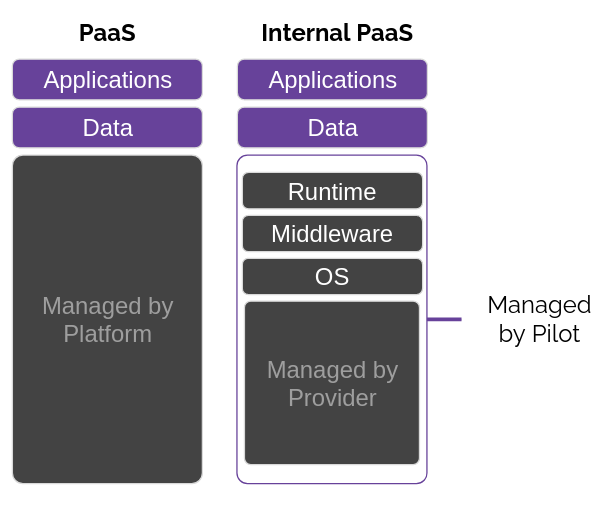
As a reminder, a PaaS manages everything for you, taking away control and configurability to provide ease-of-use. The platform provider, such as Heroku, manages the infrastructure themselves - potentially even using an IaaS provider. In Heroku's case, they build on top of AWS services.
An internal, or self-hosted, PaaS still provides the ability to control and configure the platform as long as you have the expertise, while still providing sensible defaults so that novice users don't have to worry about the underlying services. In Pilot's case, developers can provision that internal PaaS on either GCP or AWS - so the cloud provider still manages the underlying hardware - and Pilot manages the necessary IaaS services that we utilize, which we will discuss in section 5.
4 Who Should Use Pilot?
When it comes to utilizing a platform, companies generally consider three options: build, buy, or operate.
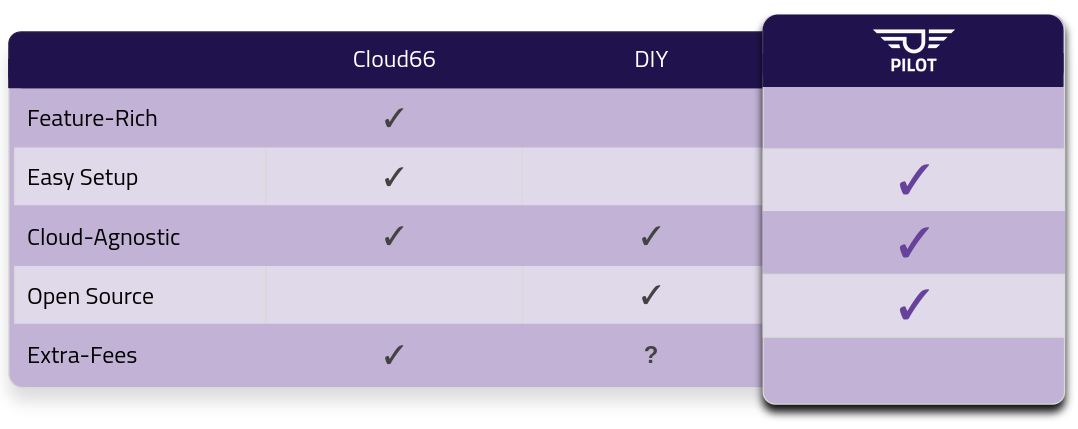
The first option, build, simply isn’t feasible for a small company. If you’re a tech giant like Netflix or Atlassian, with a huge budget and experienced DevOps engineers, you can roll your own internal platform. For a small company, their time is much better spent on their own core-business product that keeps the lights on.
If a small company like ACME were to buy a solution, they might look at working with a PaaS vendor like Cloud66. Utilizing a platform vendor makes the whole process very easy and painless, but that ease comes with a pretty steep price. Not every small company has enough runway to justify spending money on a highly-scalable platform.
Pilot exists in the third option, operate. Our open source solution makes it relatively simple to spin up your own internal PaaS without breaking the bank and without being overly complex for a small team to manage and maintain. And if they have the time, they can even extend it to fit their own use cases.
5 Pilot's Architecture
Pilot consists of two main parts, the server and the CLI.
5.1 Pilot CLI
The Pilot CLI is what provisions the Pilot Server and how we can communicate with it after it's provisioned. The functionality of the CLI is covered in greater detail in section 6.
5.2 Pilot Server
The Pilot server is provisioned using Terraform. A main.tf file is dynamically generated for either an AWS EC2 instance or a GCP Compute Engine
instance depending on what flag the user provides. Terraform then provisions a virtual machine that will host our custom Waypoint containers which will run in
Docker.
We also used a tool called cloud-init to help us bootstrap the virtual machine with the proper software and configure it the same way every time. Cloud-init allowed us to create identical clones of the Pilot server across different cloud providers.
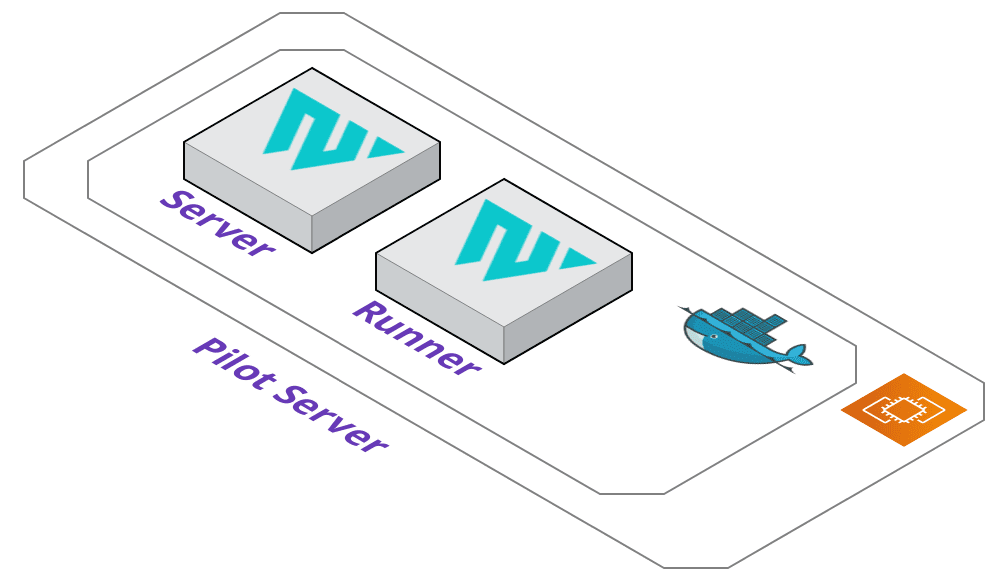
The containers running on the Pilot Server are a Waypoint server and Waypoint runner. The Waypoint server handles incoming requests, serves the user interface,
and caches project metadata. The runner handles the execution of the deployment lifecycle. Whenever a command is executed, such as pilot up, the
server receives the request, understands that it is a deployment command, then tells the runner to handle the execution for the proper application.
Instead of using the default Waypoint image provided, we needed to create our own custom Waypoint image so that the runner container can have everything it needs to handle the deployment process. We discuss this further in section 9.2.
5.3 Pilot Database
Pilot also provisions a global PostgreSQL database for applications to use. The caveat is that only applications deployed on the same cloud provider as the database can access it. For example, an application deployed on Elastic Container Service would not be able to communicate with a Cloud SQL instance without manual configuration.
GCP Cloud SQL Instance
When running the command pilot setup --gcp, Pilot will provision a Cloud SQL instance using PostgreSQL.
To provide a layer of security, the database is limited to communicating via an internal IPV4 address with services in the same
VPC. We also provision a VPC Connector that allows for communication between a Serverless service, such as an application
running on Google Cloud Run, and the database.
AWS RDS Instance
When running the command pilot setup --aws, Pilot will provision an RDS instance using PostgreSQL.
To allow applications to communicate with the database, we also provision a subnet group and security group that
applications can be tied to.
Database Configuration
During setup, Pilot configures a database user for your applications to use. Any extra configuration will
need to be handled via the respective cloud provider's management console. Any necessary connection information
can be retrieved via pilot server --db; this will return the database address, user, and password.
5.4 Application Deployment
With a waypoint.hcl configuration file, Pilot can be used to deploy applications with a variety of configurations.
We wanted to give flexibility to our users, so these configuration files are freely editable for your needs but we do provide some sensible defaults to play around with.
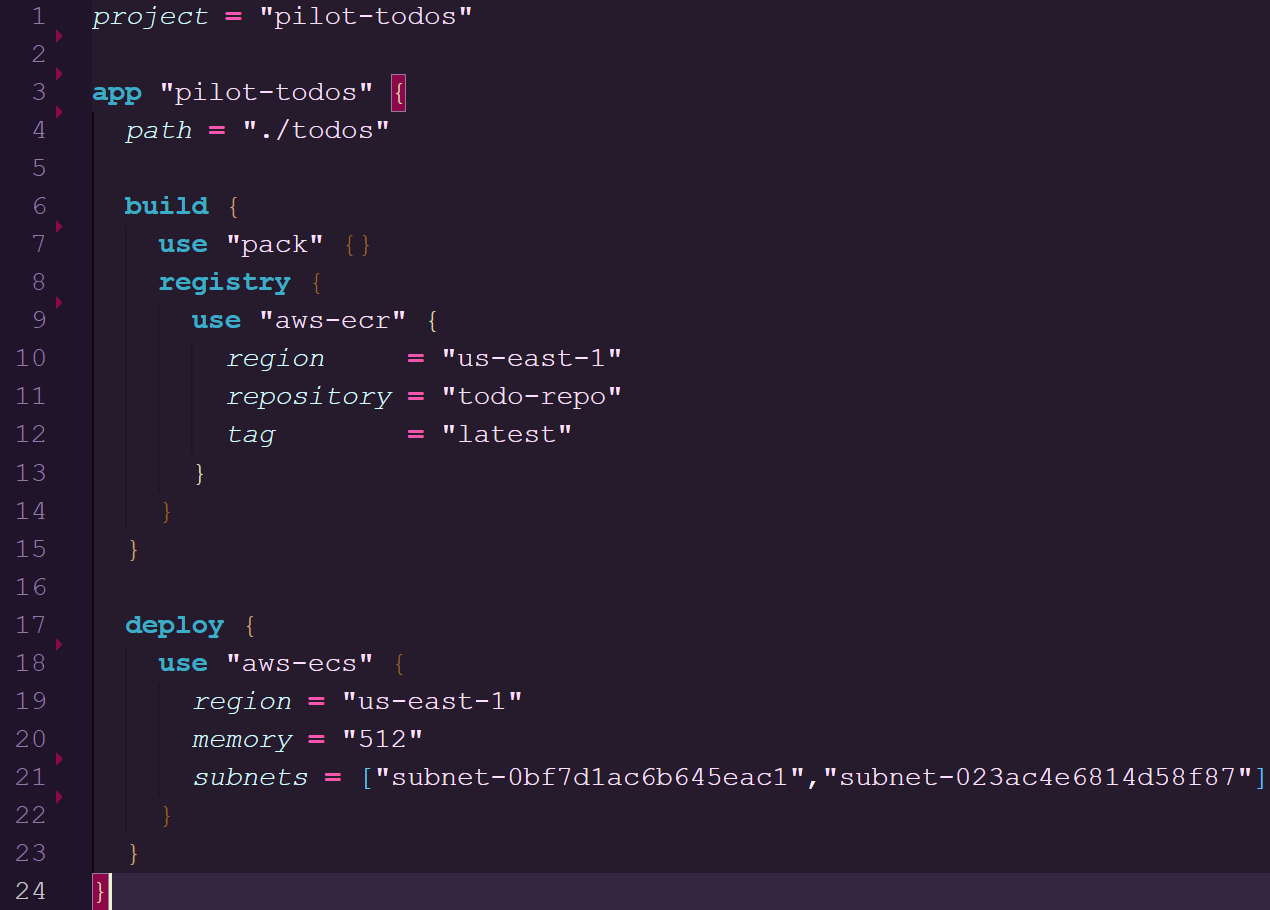
waypoint.hcl configuration used to deploy on ECS
Here we will dive into the architecture of the deployment lifecycle being build, deploy, and release as well as how it pertains to the stanzas within a waypoint.hcl.
Build
The build stanza defines how the application should be built into an image and where the image should be stored.
You can use Docker or Pack as builders to compile source code into an image.
A Docker build will require a Dockerfile in your project repository that is used to configure the dependencies needed for the application.
The Dockerfile places more of a demand on the part of the user to figure out what is needed for their application to run properly.
This can lead to oversized images if software is installed that is not actually needed.
Going with Pack for the build phase will use Cloud Native Buildpacks. Pack will analyze the source code of your project to determine the language and any necessary dependencies. After this analysis, Pack will apply any relevant buildpacks that can be used to build a runnable artifact without the user defining it themselves. This compilation of buildpacks creates a container image that can be used to spin up containers within a platform.
Once the artifact is built the image is pushed to a container registry which in Pilot's case can be a AWS Elastic Container Registry or Google Cloud Container Registry repository.
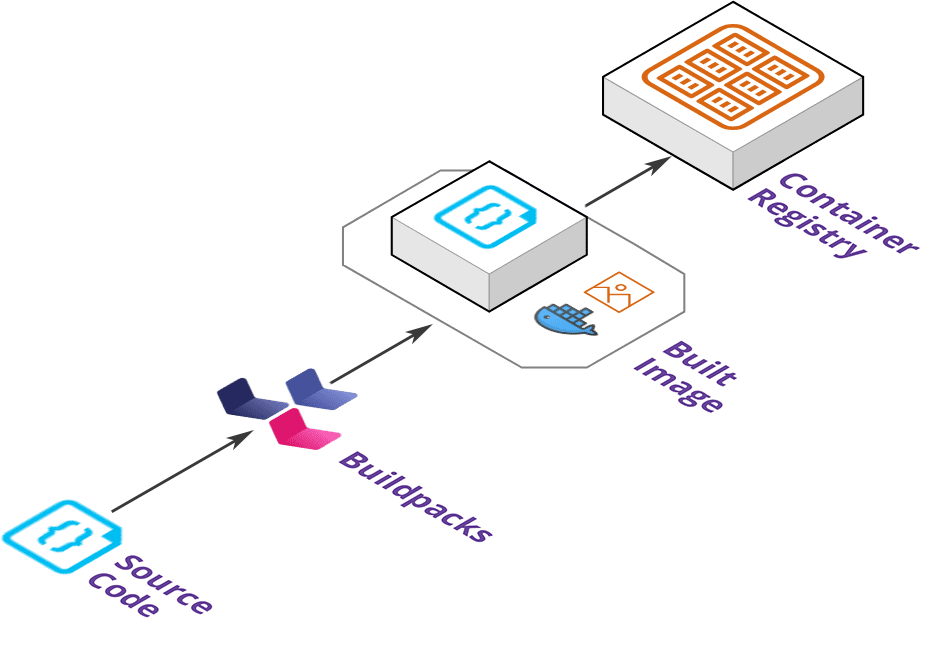
Deploy
The deploy stanza defines how an application is deployed on the cloud provider.
It will take the built artifact from the registry and deploy it to a target deployment platform such as AWS Elastic Container Service or Google Cloud Run cluster.
This allows Pilot deployed applications to run on a managed platform without a user needing to configure container orchestration such as networking and autoscaling resources.
The deploy phase is also where applications are staged for release.
Staging refers to the application being ready to receive traffic but is not open to public consumption by adding a load balancer or updating DNS records.
Some platforms do not support staging like in the case of ECS which the deploy stanza serves as both the deploy and release phases.
In addition, this section of the configuration file can be used to define specifics once the container is deployed such as CPU and memory constraints or port number the application will listen on.
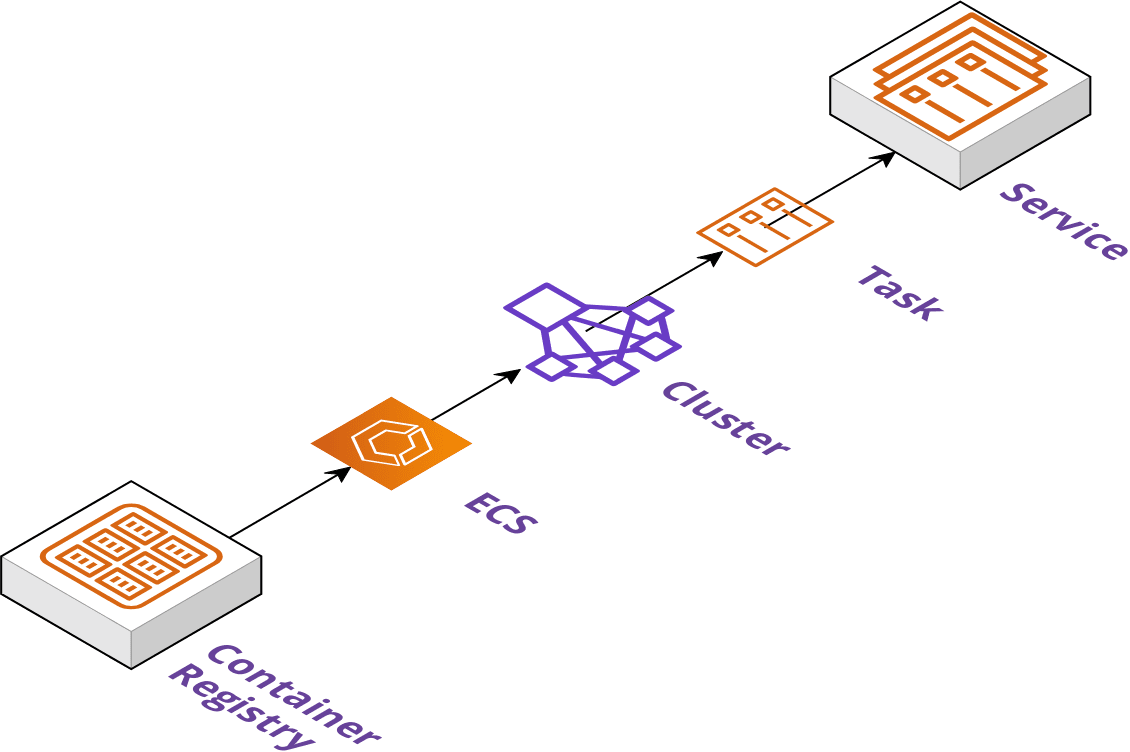
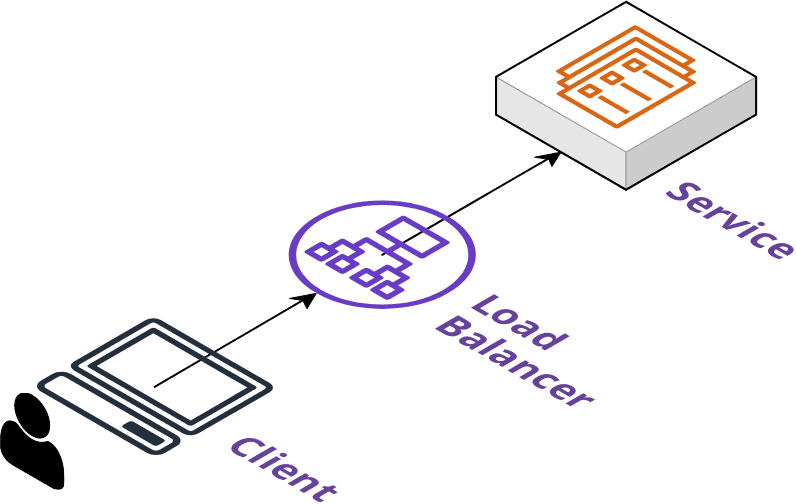
Release
A release stanza defines the final phase of deployment. As mentioned in the previous section this is typically where the application is opened up for general traffic.
The release phase is considered optional depending on the plugins being employed. It will generally attach a load balancer to an application, assign a DNS record,
and any other configuration needed to make the application available on the internet.
6 Installing and Using Pilot
6.1 Installation
Pilot is an NPM package that can be installed using npm i -g @pilot-framework/pilot
6.2 Set Up Pilot Server
pilot init
pilot init sets up your local environment. It downloads binaries Pilot needs like Terraform and Waypoint, and also scaffolds our metadata
directory, ~/.pilot, which contains any necessary information Pilot needs to operate.
pilot setup [PROVIDER]
pilot setup [PROVIDER] provisions a virtual machine in the chosen cloud provider. The architecture previously shown depicts an AWS EC2 instance but it can be a
GCP Compute Engine instance as well. Setting up the Pilot Server can take a few minutes to finish provisioning because it has to provision a VM, provision a database,
install all the necessary software the Pilot Server needs, and finally configure the local environment to communicate with the server.
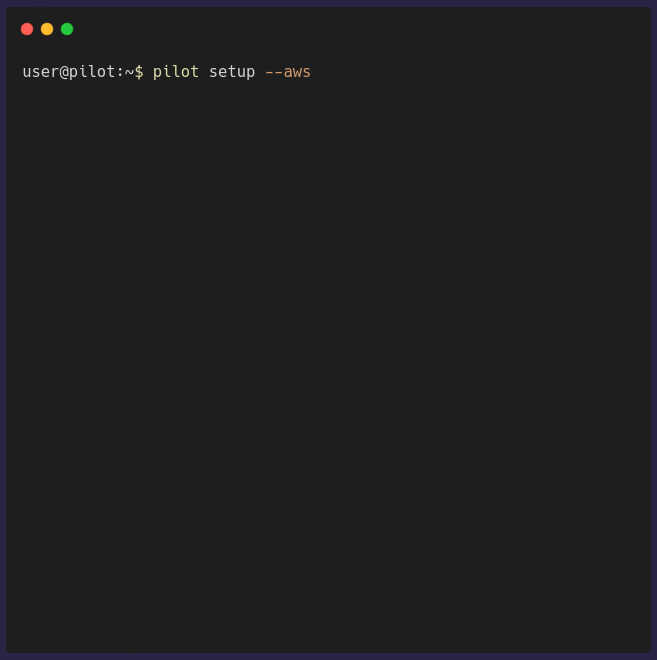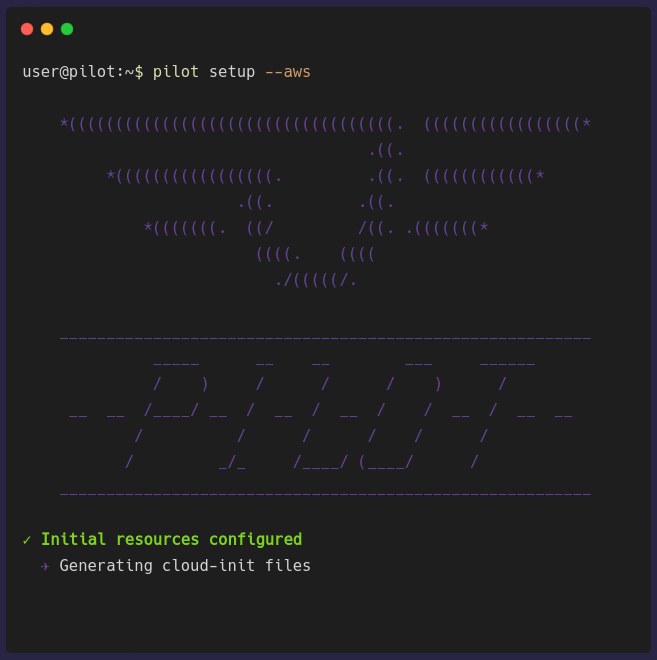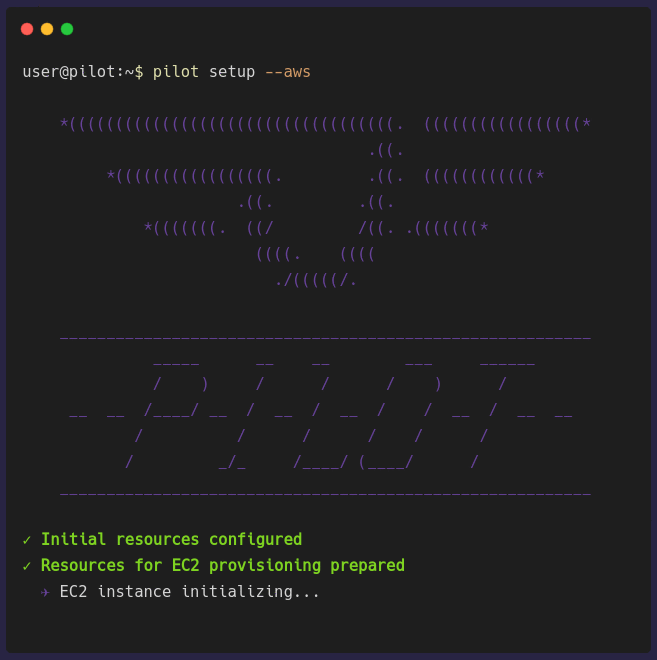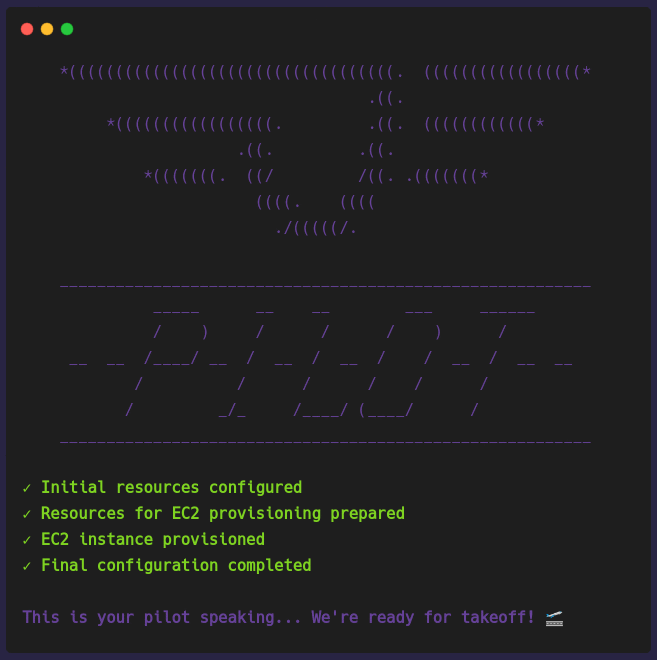
Once the Pilot Server is provisioned and configured, you're able to deploy your applications.
6.3 Deploy an Application
Deploying an application is a three step process:
- Creating the Project
- Creating and Configuring the Application
- Deploying the Application
Creating the Project - pilot new project
First, you need to create the project to deploy on the Pilot server. It's as simple as calling pilot new project. The command will prompt for the name of
the project and will register it with the Pilot Server. This action can also be done via the provided UI.
Creating and Configuring the App - pilot new app
pilot new app configures general information about your application. It will prompt you for some of the necessary information that is needed to
deploy your application like what cloud provider to deploy to, the application name, and other pertinent information.
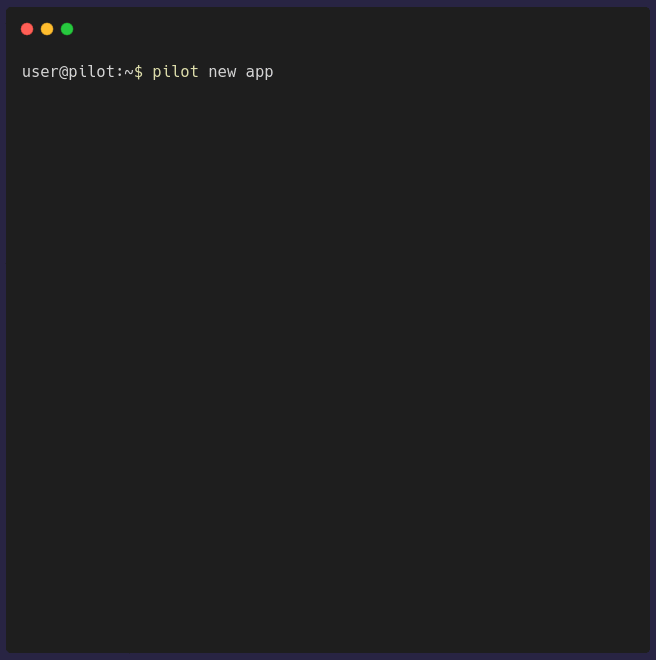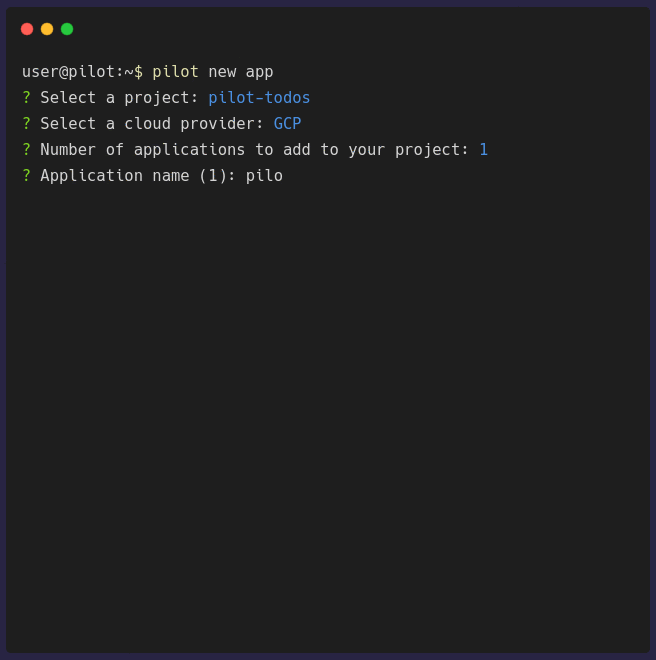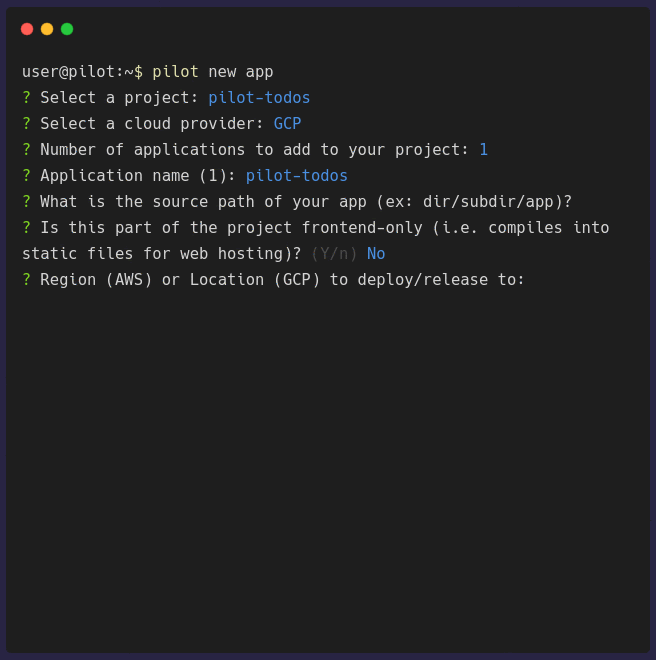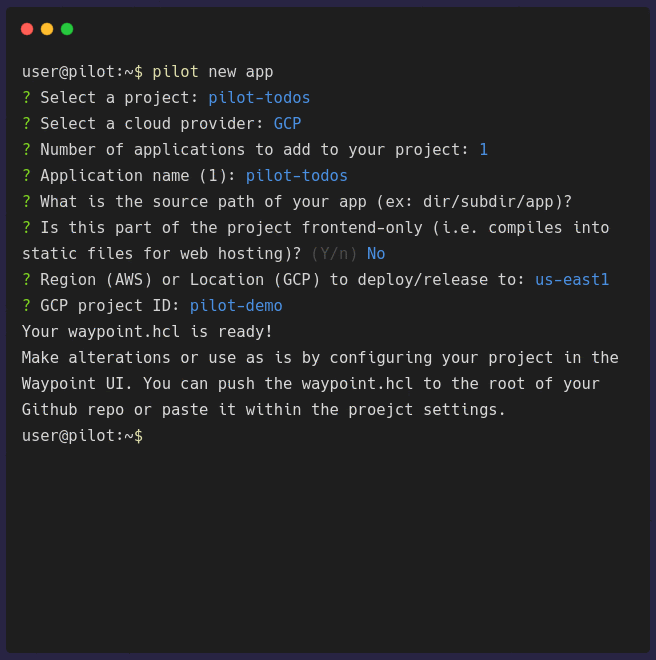
Once the configuration is complete, a waypoint.hcl file will be generated. You need to push this into the root of your application repository before you can
deploy it. Or, if you prefer the waypoint.hcl to not be checked into your repository, you can copy the file contents, and paste it within the UI when
selecting the location of the waypoint.hcl file.
Creating and Configuring the App - UI Configuration
From the UI, you need to configure your app and link it to your remote repository. More information on how to do this can be found via Waypoint's documentation.
Deploying the App - pilot up [PROJECT]/[APP]
pilot up is called with the project name and app name as arguments. It will look at the waypoint.hcl file and go through the three phases of
deployment: build, deploy, and release.
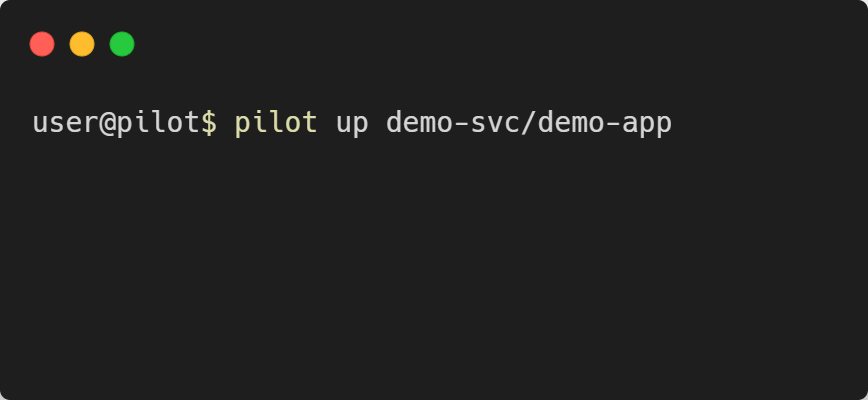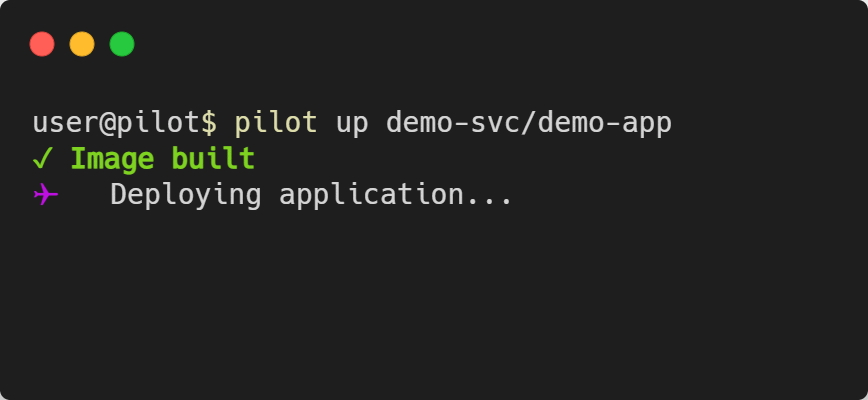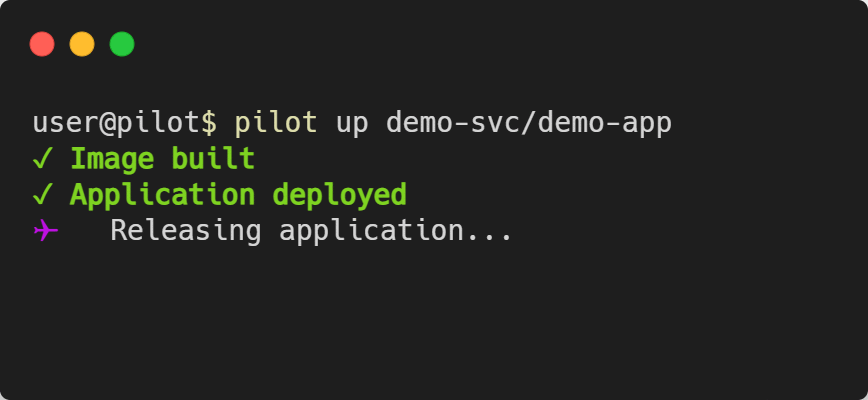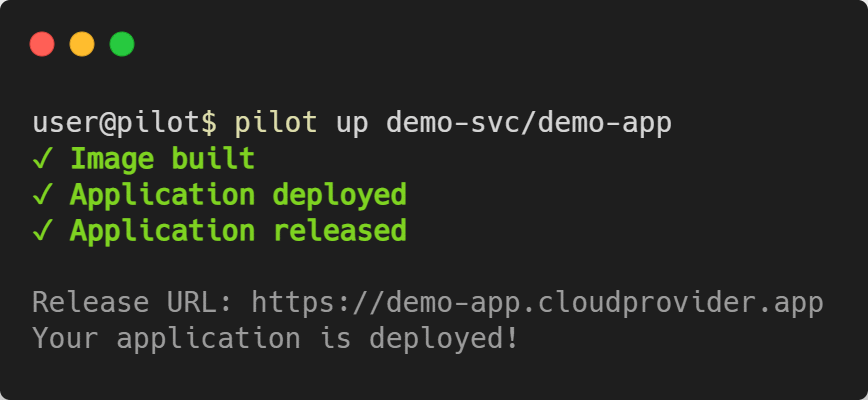
Keep in mind that depending on your application and cloud provider, the deployment process can take multiple minutes to complete.
7 Design Decisions
Our design intention while developing Pilot was to make it easy for a small team of developers to focus on writing code and deploying their applications with a cloud-agnostic approach. They will not have to worry about the underlying infrastructure, just that their applications are made available for consumption while still having control of the platform and choice of provider. The main design decisions centered around using Waypoint as a deployment tool and how to install it to handle remote operations.
7.1 Extending Waypoint
An integral decision for Pilot was to extend Waypoint. It is a fairly new product in the open source deployment space but gives you various options around image builds and deploying applications to multiple cloud providers. Using it as base for Pilot's design provided several benefits.
Existing User Interface
We were able to focus on CLI and infrastructure development since Waypoint has an existing user interface. It is well-designed and provides a simple to understand user interface.
Custom Plugin Ecosystem
The Waypoint SDK allowed us to develop our own custom plugins in Go. This enabled us to add in static web hosting as a deployment option using our Cloudfront and Cloud CDN plugins.
Trusted Open-Source Company
Waypoint was developed by HashiCorp, which we consider to be a trusted open-source company. They are well known and have products that many companies have incorporated into their multi-cloud strategies.
Familiarity with HashiCorp Configuration Language
Developers that have used HashiCorp's products are also familiar with their HashiCorp Configuration Language. You would recognize it if you have used their products like Terraform, which is a popular infrastructure automation tool. The syntax of the configuration files is meant to be easy to read and write.
7.2 Handling Remote Waypoint Operations
Remote collaboration is an important aspect of a PaaS, but can introduce roadblocks when implementing your own.
Steps to Set Up Waypoint
As of right now, it is difficult to configure Waypoint as a remote management option. If a team wanted to integrate Waypoint into their platform, they would have to consider a few design decisions of their own.
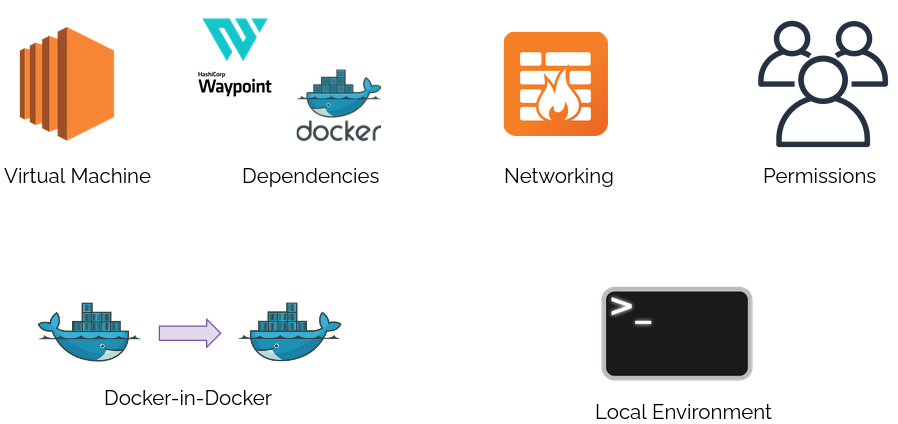
First, you would need to provision the necessary infrastructure for remote operations, which could be an AWS EC2 virtual machine. Then install and configure dependencies, such as Waypoint and Docker, to be able to deploy applications to the cloud. Setting up networking and rules for the EC2 instance is also a necessary step to ensure your instance is secure.
The Waypoint server would also need the proper permissions, such as service credentials for all cloud providers you would want to deploy to. Additionally, Waypoint's documentation recommends configuring Docker-in-Docker for a remote Waypoint runner to handle building and pushing images to a container registry. Finally, you have to configure your local environment to communicate with the established remote pipeline.
We believed automating this process would remove a large pain point for our users.
Using a Remote Waypoint Server
We decided to use a remote Waypoint server to serve as the backbone of Pilot's deployment operations to multiple cloud providers. But you might be wondering: why was it a good option to create a remote Pilot server in the first place?
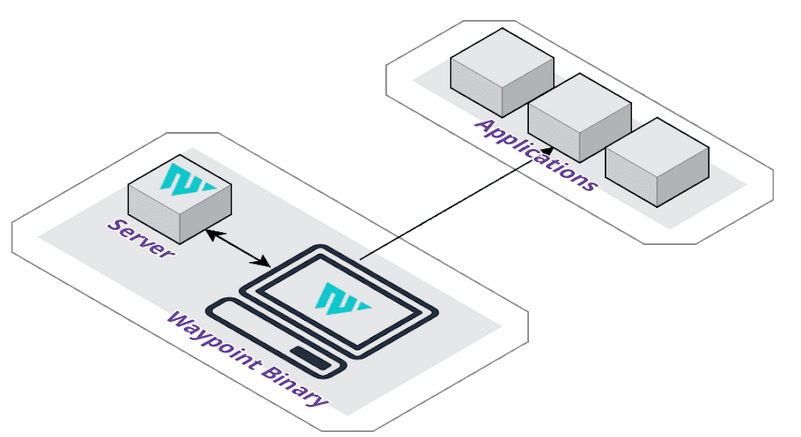
As you can see, a simple Waypoint configuration is much easier when set up locally. All that it requires is a Waypoint binary and a server container running on your local machine. A runner container is not necessary for taking on deployment jobs, since the Waypoint binary will serve as the runner in this type of configuration, which is less management overhead.
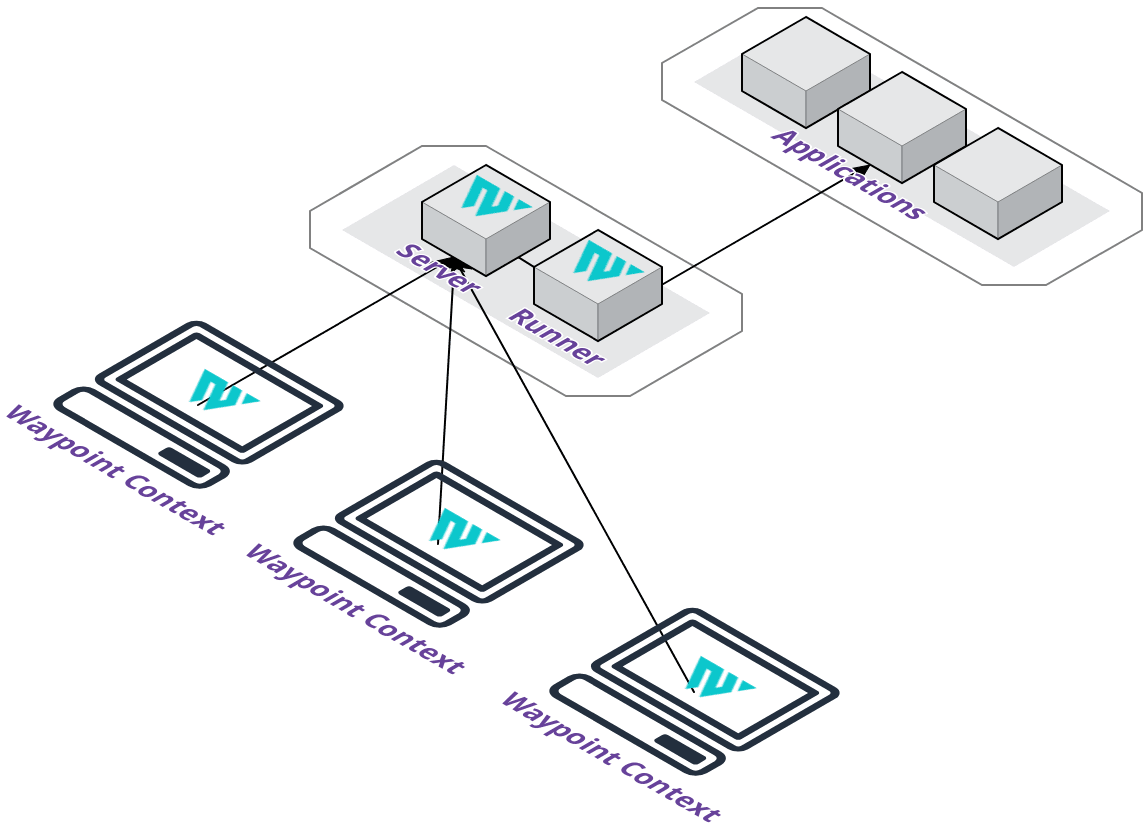
A remote Pilot server, on the other hand, would enable us to provide increased flexibility for our users. The Pilot server can be provisioned on our supported cloud providers to easily allow collaboration with a team. Users will not have to configure their local machine to be accessible on a network and you get a centralized management server for project and application deployments.
We also take away the concern of installing local dependencies for the deployment lifecycle. You will not have to install Docker, Pack, or any additional tooling since they are available on the Pilot server. However, we do provide the flexibility of managing the Pilot server through SSH access.
Having a remote Pilot server is good and all, but how should we install the Waypoint server to it? Waypoint allows installing servers and runners using Docker, Kubernetes, and even HashiCorp’s Nomad orchestration service. For Pilot, the options came down to Docker and Kubernetes as an installation platform for our containers.

With Kubernetes orchestration, we could spin up a cluster that would give us the benefits of high availability and scalability. Having multiple runners set up on a cluster would be able to handle concurrent deployments of applications. This would be a value-add for teams wanting simultaneous deployments without a wait time. A cluster could also have self-healing capabilities to bring containers back up if they were to go down.
That all sounds great, but Kubernetes has some drawbacks for users new to it.
Kubernetes will introduce extra overhead for smaller development teams. It is difficult to understand and implement as you will be spending a lot of time in documentation to wrap your head around proper configuration and management. With that in mind it is not the best option if you want to get up and running quickly.
Kubernetes clusters can also be difficult to maintain without a dedicated DevOps engineer or team member who has DevOps experience.
With Pilot we decided to make the Pilot server virtual machine provision a single server and runner container on Docker as a platform. Through our testing as a small development team, a single Waypoint server and runner was enough for our needs. This makes it easier for users as they will only have to manage a single virtual machine along with a couple of containers, and not the headache of a Kubernetes cluster on top of it.
Runners are considered an advanced configuration but you could spin up more on the Pilot server if needed with documentation available on the Waypoint site.
8 Implementation Challenges
There were three major challenges we ran into while developing Pilot: creating Waypoint plugins, building out a custom image capable of handling our Waypoint operations, and whether to use Docker-in-Docker for image builds.
8.1 Creating Waypoint Plugins
Plugins are binaries written in Go that implement one or more Waypoint components. Waypoint components consist of the deployment lifecycle such as building artifacts and pushing them to a registry. You can think of them as middleware that Waypoint injects into the lifecycle.
When we started learning about Waypoint, we realized that many of the built-in plugins were geared towards deploying full-stack or backend applications. We felt there was an opportunity for plugins that were able to deploy static assets from something like a React application, so we were happy to see Waypoint provides an SDK that allow developers to create their own plugins. You can create plugins that execute for the entire build, deploy, and release cycle or individual parts of it.
Pilot has several plugins created for your use that come baked into our custom Waypoint image.
- A Yarn plugin executes during the build phase to bundle frontend applications into static files.
- An Amazon Cloudfront plugin that interfaces during the deploy and release phases. This plugin will upload static files to S3 and release a static site to a Cloudfront distribution.
- Finally, a Cloud CDN plugin for GCP that works like the Cloudfront plugin by uploading static files to Cloud Storage and releasing on Cloud CDN.
Developing these plugins introduced their own challenges. For one, the documentation for creating plugins was a bit light on context. It and the associated tutorial focuses mainly on the build phase. Since the information for additional components was more conceptual, we needed to reference source code of the built-in plugins, custom plugins from other developers, and trial and error to get the functionality we wanted.

Another problem was SDK support depending on the cloud provider. We found the AWS SDK to be robust and easy to work with. Anything we needed to provision for deploying to Cloudfront could be done using it.
The GCP SDK, however, was limited in some ways. Creating Cloud Storage buckets and uploading assets was supported, but provisioning the resources needed for a Cloud CDN release was not. Additionally, deleting certain resources using the SDK was also partially supported, which was a drawback when wanting to teardown those resources automatically.

We decided to use a combination of the SDK with the gcloud CLI to give us the same functionality as the Cloudfront plugin. We created a wrapper for gcloud commands to provide familiarity and usability as an SDK and it worked out fine for our needs.
However, needing the gcloud CLI installed created a dependency on our Waypoint containers when deploying front-end applications using our Cloud CDN plugin.
8.2 Building a Custom Docker Image
By default, Waypoint uses HashiCorp's Waypoint image which can be found publicly available on Docker Hub. It includes the Waypoint binary and built-in plugins developed by HashiCorp. But this introduced a problem for our team when it came to adding our own plugins.
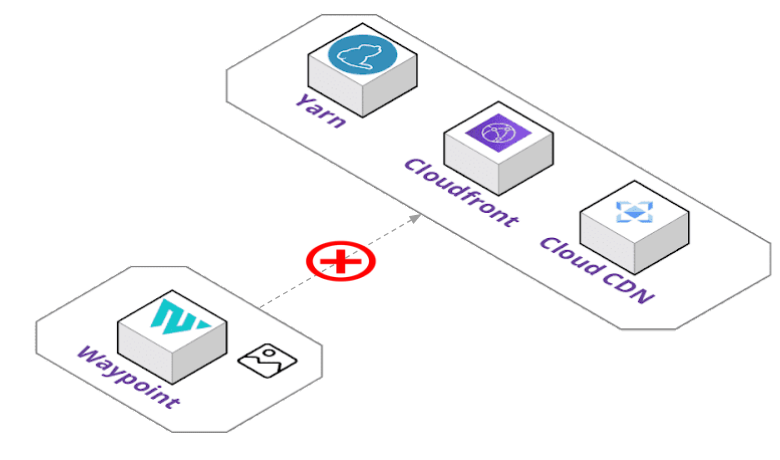
We wanted to include our custom plugins for Yarn builds and Cloud CDN and Cloudfront deployments. At this time, Waypoint does not currently have a community plugin system for making custom plugins generally available. Our plugins also had their own dependencies, like NodeJS and Yarn to build static files and gcloud CLI for Cloud CDN provisioning.
We decided to create our own custom Waypoint development and release images that can be pulled from Docker Hub freely. To do this, we had to reverse engineer Waypoint's default image and source code to figure out how Waypoint starts the server and runner containers, but also what packages the Waypoint image had internally.
Our investigation found the image was pretty much a barebones Linux distribution limited to the Bourne shell. Not much else stood out in terms of dependencies for normal Waypoint installations. This meant using that image as a base would require installing multiple standard Linux packages in our Dockerfile.
We initially started off with a standard Node image and only needed to install gcloud as a dependency. This worked fine, but the resulting image was unnecessarily large at approximately ~1.6 gigs. The Node image has other packages installed we really did not need. Waypoint server installs took longer as a result.
We were keen on downsizing the image build as much as possible and attempted multiple prototypes. Eventually, we discovered an alpine image that Google maintains which contains gcloud and decided to use it as a base for our custom image. This cut down the bloat by 50% and increased performance of our Waypoint server installs using Pilot's image.
8.3 Docker-in-Docker Image Builds
Another challenging aspect of remote Waypoint operations is executing image builds and pushes to a container registry from a runner container. There are several so called Docker-in-Docker methods that one may use to accomplish this with a few outlined below.
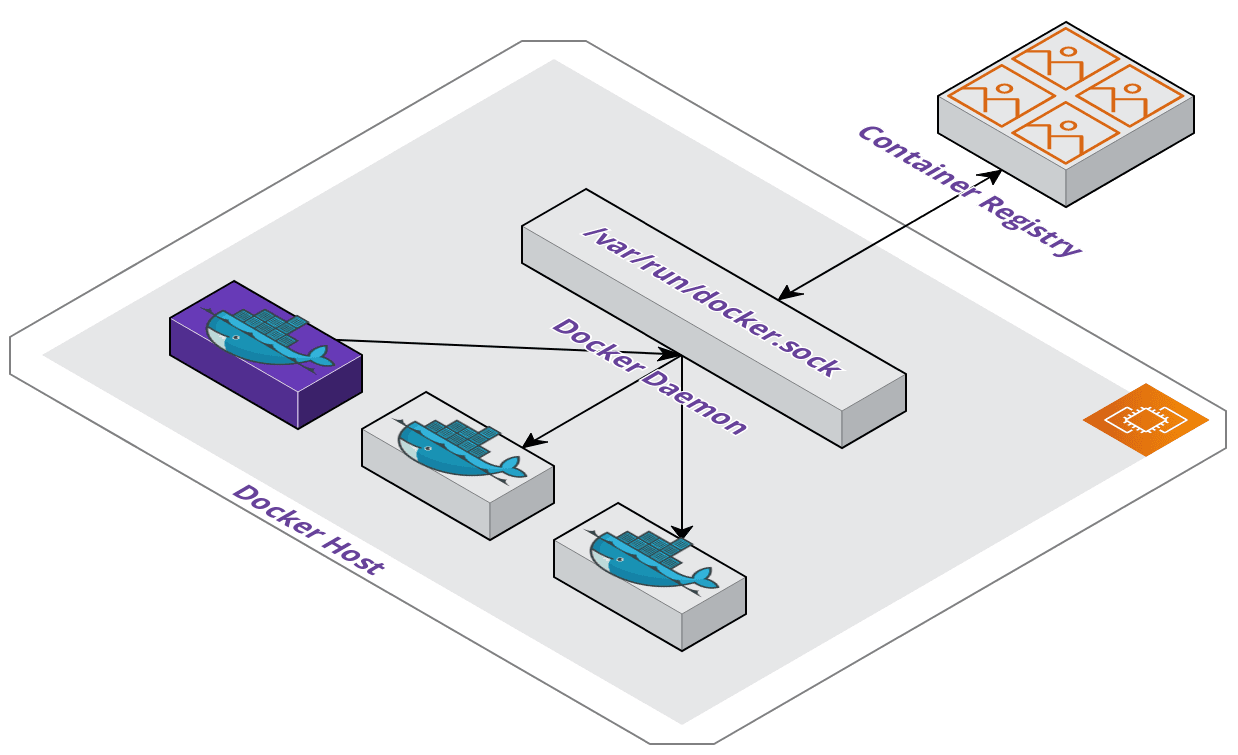
The first method uses the docker.sock which is the default Unix socket that
the Docker daemon listens to. From a Docker host you run a command that starts a container
with a Docker binary installed and mount the host's socket path to allow running Docker
commands from within the container. When commands are executed, all operations happen on
the host such as image builds, pushes, and container starts. Any started containers become
siblings of the container issuing the commands.
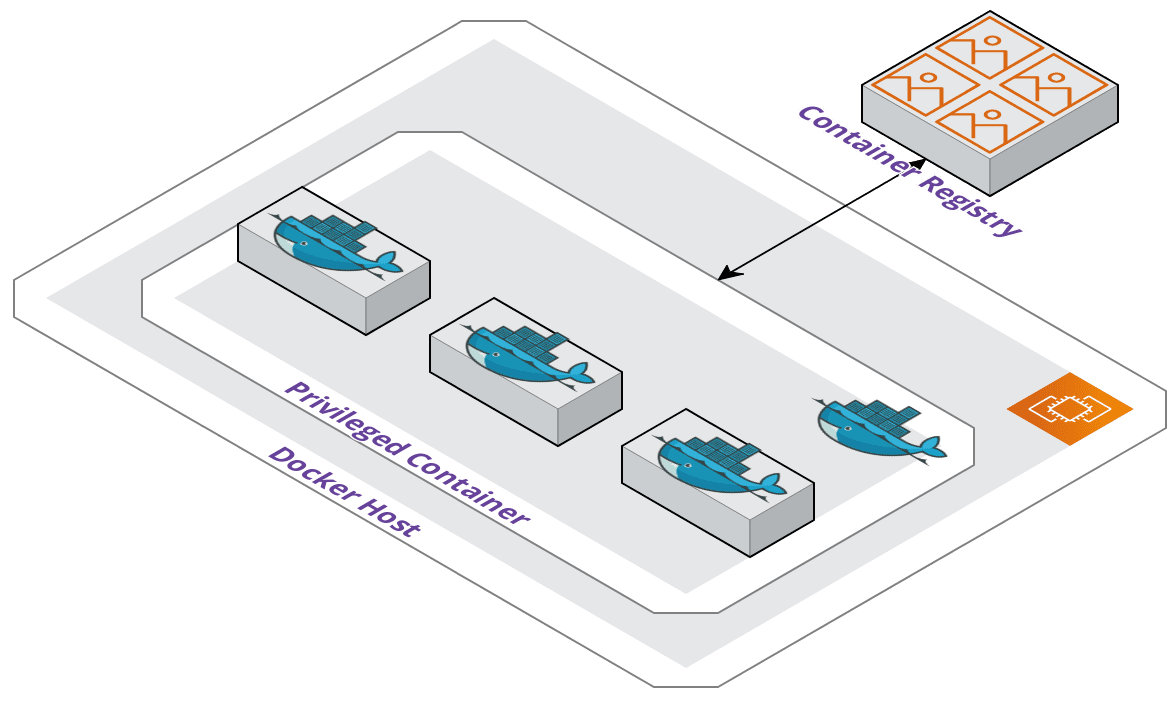
The second method uses an outer container started from an official Docker-in-Docker image that Docker maintains. A container must be started in privileged mode which can have adverse side effects.
The container will get full access to all devices on the host. Consequently, this is the same access to the host as any processes running outside of containers, which can be a security flaw if the privileged container were to be compromised.
Additionally, all Docker operations would occur within the container. Images would be built and stored on the container which is not great when containers should be lightweight. Started containers would become children and nested within the outer container and this creates additional management overhead with the amount of abstraction.
Evaluating Docker-in-Docker generated its own problems. It is generally not recommended due to the issues mentioned previously and more, as it is meant for niche use cases such as developing for Docker or using it in continuous integration. Even when using it for continuous integration, it is often seen as a last resort.
We also did not want to clutter our custom image with a Docker installation if all
that was needed is build and push capabilities for deployments. Another issue is
that Waypoint handles starting the server and runner containers, so there is no
control over mounting the docker.sock as a volume, as seen in the first method, nor
starting a container in privileged mode with the second method.
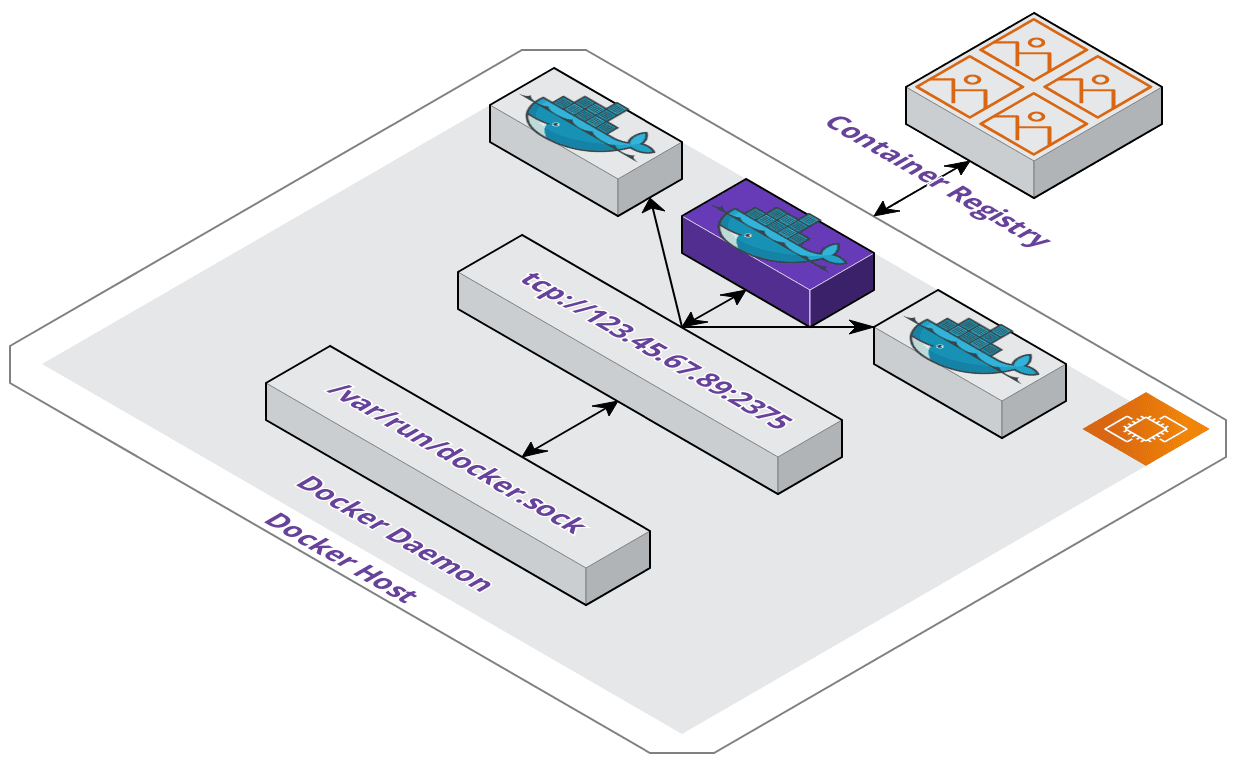
Our solution was to make the host, being our Pilot server, a Docker server and
expose Docker as an API for the runner container to consume. This looks and feels
like Docker-in-Docker, but is not since we do not need a Docker installation on
the container. It also isolates Docker operations to the host where Docker is
installed. All we needed for the runner was to set a DOCKER_HOST environment
variable referencing the host address and port.
When the container needs to build and push images it makes requests to the API without needing Docker installed itself.
This worked to be a viable option but it introduced another problem and that was malicious attackers scanning for misconfigured Docker APIs. With a Docker server port completely exposed it is essentially giving root access to the host machine.

We ran into a group called TeamTNT, who take over Docker processes, install
their image, and start a container. The container is used to compromise the host
machine by mounting the host's /bin/sh path as a volume and using the chroot command
to run a process on that path. Typically they will implement a crypto miner on the host machine.
Various issues were raised by this exploit during development and testing application deployments. A possible solution would be to use TLS so the requester would have to be authorized. Another solution, and one we chose, was to lock down the configured Docker server port 2375 with a security group or firewall rule on the respective cloud provider. This way the only allowed source traffic has to come from the same address as the server and keeps the runner container on a Docker network.
9 Future Work
There are many features we would like to add to Pilot but we have a key few that would round out and bolster its capabilities and ease of use.
- We want to add support for a wider range of cloud providers as Pilot currently only supports for AWS and GCP.
- A user interface for database management would provide central management rather than having users go through a cloud provider's management console.
- Make configuring environment variables of applications easier through a UI component. There are multiple ways environment variables could be set but a few options are within a waypoint.hcl file or using the Waypoint CLI on an application or project level.
- Lastly, we would like to support more Infrastructure as a Service offerings during our application initialization process. With AWS for example, we default the generated configuration file to deploy applications using Fargate on ECS but you could also use EC2 or lambda deployments by modifying the generated waypoint.hcl file.
10 Presentation
11 References
https://www.infoq.com/news/2017/06/paved-paas-netflix/
https://blog.developer.atlassian.com/why-atlassian-uses-an-internal-paas-to-regulate-aws-access/
https://dzone.com/articles/netflix-built-a-paaswhy-cant-i
https://arxiv.org/pdf/2008.04467.pdf
https://devopscube.com/run-docker-in-docker/
https://linuxhandbook.com/docker-remote-access/#what-is-docker-remote-access
https://www.waypointproject.io/docs/internals/execution
https://www.waypointproject.io/docs/extending-waypoint
The Team


